Kernpunkte:
- Plattform Privatheit
- Transparenz für das Internet der Dinge
- AnoMed – Anonymisierung für medizinische Anwendungen
8 Modellprojekte und Studien
Das Unabhängige Landeszentrum für Datenschutz hat als Behörde der Landesbeauftragten für Datenschutz seine Aktivitäten in drittmittelfinanzierten Projekten und Studien fortgesetzt. Damit kooperiert das ULD weiterhin aktiv mit der Wissenschaft und kann zusammen mit Wissenschaftspartnern proaktiv an der Erforschung datenschutzspezifischer Fragen und der Gestaltung einschlägiger Technologien mitwirken. Gefördert wurden die im Berichtsjahr laufenden Projekte seitens des Bundesministeriums für Bildung und Forschung (BMBF), teils mit Co-Förderung durch die Europäische Union (NextGenerationEU). Beteiligungen an Projekten erfolgten weiterhin primär dort, wo daten-
schutzfördernde Technik (englisch: „Privacy-Enhancing Technologies“, kurz PETs) erforscht, entwickelt oder in die Praxis transferiert wird oder wo besondere Risiken für die Rechte und Freiheiten natürlicher Personen bestehen.
Im Jahr 2024 beteiligte sich das ULD an Projekten zu aktuellen Themen in den Bereichen Privatheit und selbstbestimmtes Leben (Tz. 8.1), Überführung von Lösungen des Datenschutzes durch Technikgestaltung in die Praxis (Tz. 8.2) sowie Transparenzprobleme des Internets der Dinge (Tz. 8.3). Zudem setzte das ULD sein Engagement zu Anonymität für Medizinforschung mit Gesundheitsdaten fort (Tz. 8.4).
8.1 Plattform Privatheit: PRIDS – Privatheit, Demokratie und Selbstbestimmung
Über das Verbundvorhaben „PRIvatheit, Demokratie und Selbstbestimmung im Zeitalter von KI und Globalisierung – PRIDS“ hatten wir schon berichtet (40. TB, Tz. 8.1; 41. TB, Tz. 8.1; 42. TB, Tz. 8.1). In dem von April 2021 bis Mai 2024 laufenden Projekt beschäftigten sich sieben Konsortialpartner aus verschiedenen Perspektiven mit der digitalen Transformation von Gesellschaften. Diese wird u. a. durch soziale Medien, Systeme der künstlichen Intelligenz (KI) und weitere technische Entwicklungen geprägt. Das ULD konzentrierte sich dabei auf den Bereich „Grundrechtsschutz in globalen Technikinfrastrukturen“ und beteiligte sich an den interdisziplinären Forschungsarbeiten des Gesamtvorhabens zu Fragen von Datenschutz- und Privatheitsaspekten in Bezug auf Demokratie, künstliche Intelligenz (KI) und verschiedene Situationen im Verlauf der Lebensspanne von Individuen.
Prägend für das Vorhaben war die Vernetzung innerhalb der Plattform Privatheit (vormals: Forum Privatheit) sowie mit Akteuren aus Wissenschaft, Politik, Wirtschaft, Verwaltung und Zivilgesellschaft, um den öffentlichen und fachlichen Diskurs voranzubringen. Zu berücksichtigen war dabei die regulatorische Entwicklung auf europäischer und nationaler Ebene.
Die Weiterentwicklung vom Forum Privatheit (40. TB, Tz. 8.1) zur Plattform Privatheit fiel in die Projektlaufzeit von PRIDS. Es handelt sich dabei nicht um eine Umetikettierung, sondern der Charakter des Projekts hat sich zu einem Dach für eine Vielzahl von interdisziplinären Projekten gewandelt. Forschende entwickeln aus unterschiedlichen Perspektiven rechtliche, technische und organisatorische Lösungen, die es ermöglichen, in unserem digitalen Alltag unsere Grundrechte und europäischen Werte zu wahren. PRIDS gehörte zu den Kernprojekten in dieser Phase des Übergangs zu einer Plattform.
Ein großer Teil der im PRIDS-Projekt entstandenen wissenschaftlichen Veröffentlichungen ist über die Website der Plattform Privatheit als Open Access verfügbar, beispielsweise die Tagungsbände der jährlichen Konferenz der Plattform Privatheit, an der wir über das Projekt PRIDS maßgeblich mitgewirkt haben. Hinzu kommen White Paper und Policy Paper, die ebenfalls zum Download bereitgestellt werden:
https://www.plattform-privatheit.de
Kurzlink: https://uldsh.de/tb43-8-1a
8.2 Projekt DatenTRAFO – Neue Datenschutz-Governance – Technik, Regulierung und Transformation
Im Projekt „DatenTRAFO“, das für drei Jahre (2023-2026) geplant ist, untersuchen wir die neuen EU-Datengesetze, insbesondere die Digitale Dienste- und die KI-Verordnung (42. TB, Tz. 8.2). Beide folgen strukturell einem ähnlichen Ansatz wie die DSGVO und verlangen die Bewertung von Risiken für Grundrechte. Dabei müssen bestimmte Anbieter und Anwender Grundrechte-Folgenabschätzungen durchführen und Risikomanagementsysteme einrichten, um die Risiken für Grundrechte wirksam einzudämmen. Eine wichtige Rolle spielt insbesondere das Grundrecht auf Nichtdiskriminierung.
Im Zusammenhang mit algorithmischen Systemen, die oft als KI bezeichnet werden, gab es in der Vergangenheit bereits Probleme in den Niederlanden und vor kurzem in Dänemark. Dort wurden im Sozialbereich jeweils Systeme eingesetzt, die Sozialbetrug erkennen sollten. Allerdings zeigte sich, dass immer dann, wenn die betreffende Person weiblich war oder einen vom System als nicht westeuropäisch eingeordneten Namen aufwies, ein deutlich erhöhter Risikofaktor für Sozialbetrug angegeben wurde. Von einer neutralen, diskriminierungsfreien Berechnung eines derartigen Risikofaktors für die betroffenen Personen konnte keine Rede sein.
Im Projekt DatenTRAFO erforschen wir einen Ansatz für Grundrechte-Folgenabschätzungen, der sich am Vorgehen der Datenschutz-Folgenabschätzung orientiert und mit dem Verantwortliche auf bereits vorhandenem Wissen aufbauen können. Auf diese Weise soll gewährleistet werden, dass die Möglichkeit einschneidender Folgen für betroffene Personen, wie es beispielsweise bei einer Diskriminierung der Fall ist, frühzeitig erkannt wird und geeignete Maßnahmen getroffen werden, um gegenzusteuern. Bei einer ergebnisoffenen Herangehensweise kann es auch sein, dass Verantwortliche oder Aufsichtsbehörden zum Ergebnis kommen, dass gewisse Verarbeitungsformen oder der Einsatz von bestimmten (KI-)Systemen zu unterbleiben haben.
Das DatenTRAFO-Projekt beschäftigt sich außerdem mit datenschutzfördernder Technik und untersucht, unter welchen Bedingungen bekannte Verfahren der Privacy-Enhancing Technologies in der Praxis Verwendung finden können oder sollten. Weitere Informationen zum Projekt sind unter folgendem Link abrufbar:
https://www.datenschutzzentrum.de/projekte/datentrafo/
Kurzlink: https://uldsh.de/tb43-8-2a
8.3 Projekt Unboxing.IoT.Privacy – Transparenz für Datenschutzeigenschaften von IoT-Geräten
Dinge, die sich über das Internet vernetzen und steuern lassen? Na klar, seit einigen Jahren gehören Küchengeräte, Autos oder Hausanlagen, die mit dem Internet verbunden sind, zur Standardtechnik, die auf dem Markt angeboten wird. Das Internet der Dinge (englisch: „Internet of Things“, IoT) bringt Vorteile und Risiken der Digitalisierung und Vernetzung direkt zu den Menschen (42. TB, Tz. 8.3).
Mit dieser Situation beschäftigt sich das vom BMBF geförderte Projekt „Tool-gestützte, moderierte und bürgerzentrierte Community-Plattform zur Privacy-Einstufung von IoT-Produkten – Unboxing.IoT.Privacy“, das seit November 2023 läuft. Das Projekt setzt an dem Umstand an, dass für eine Vielzahl von IoT-Geräten die nötige Transparenz fehlt. Bereits die Tatsache einer Datenerhebung und -verarbeitung ist für betroffene Personen angesichts der geringen Größe und Unauffälligkeit der Geräte oft nicht erkennbar. Aber auch sonst haben die Nutzenden vielfach zu wenig Informationen über die Geräte und die damit verbundenen Onlinedienstleistun-
gen. Zudem mangelt es an einem Bewusstsein dafür, wer beim Einsatz von IoT-Geräten welche Datenschutzpflichten erfüllen muss.
Gegenstand des Projekts Unboxing.IoT.Privacy ist eine zielgruppengerechte zusammenfassende Darstellung von aus Datenschutzsicht relevanten Informationen über IoT-Geräte einschließlich der teils zwingend für deren Einsatz erforderlichen Onlinedienste. Diese Informationen sollen Verbraucherinnen und Verbraucher, Unternehmen und Behörden dabei unterstützen, ihre Entscheidung für einen Kauf und Einsatz solcher vernetzten Geräte informiert treffen zu können. Das Projekt baut auf Vorarbeiten der Teams der Universität Göttingen und des ULD zur Aufbereitung und Darstellung der Informationen auf (38. TB, Tz. 8.6). Im Projekt werden Software-Tools zur Analyse von IoT-Geräten entwickelt und bereitgestellt, um nötige Eckdaten über die Geräte erheben und diese darstellen zu können.
Mit dem Cyberresilienzgesetz (englisch: „Cyber Resilience Act“, CRA) wurde im November 2024 ein europäischer Rechtsakt zur Regelung von Hardwareprodukten mit digitalen Komponenten verabschiedet. Zwar geht es darin um Sicherheit und nicht primär um Datenschutz, doch gehen wir davon aus, dass damit die Informationslage zu Sicherheits- und Datenschutzaspekten für IoT-Geräte deutlich verbessert wird. Nach dem Inkrafttreten im Dezember 2024 werden die Regelungen des CRA bis Dezember 2027 schrittweise umgesetzt. Anders als unter der DSGVO belegt der CRA nicht nur datenschutzrechtlich Verantwortliche, sondern auch Hersteller, Einführer in die EU und Händler mit Pflichten, damit die grundlegenden Anforderungen der IT‑Sicherheit erfüllt werden (Tz. 2.4).
Auch wenn die im CRA vorgesehenen Maßnahmen nicht unmittelbar auf Datenschutz ausgerichtet sind, werden die bereitzustellenden Informationen eine deutliche Erleichterung für Nutzende und für Verantwortliche und Verarbeiter bei der Einhaltung ihrer Datenschutzpflichten bieten. Für die im Projekt zu entwickelnde aufbereitete Informationsdarstellung werden die Daten, die aufgrund des CRA künftig zugeliefert werden müssen, eine wesentliche Rolle spielen. Sie können ein wichtiger Ausgangspunkt für die Analyse und Bewertung sein.
Cyberresilienzgesetz (CRA)
Der Cyber Resilience Act bezweckt, ein Mindestmaß an Cybersicherheit für alle auf dem EU-Markt erhältlichen vernetzten Produkte zu gewährleisten. IoT-Produkte fallen typischerweise in den Anwendungsbereich. Neben Cybersicherheit by Design, Pflichtinformationen und einer Konformitätserklärung, dass die Anforderungen eingehalten werden, wird auch Monitoring von und im Umgang mit Sicherheitslücken geregelt.
Die Pflichten nach dem CRA können zudem bei der Konzeption einer Bewertungsmetrik für Produkte unterstützend einfließen. Dies betrifft beispielsweise Fälle, in denen nach dem CRA verpflichtende Angaben mit Datenschutzbezug fehlen oder das tatsächliche Verhalten der Geräte von der Beschreibung des Herstellers abweicht.
Mit Blick auf die künftig bestehenden Dokumentationspflichten des CRA liegt auf der Hand, Herstellern und Importeuren nahezulegen, ergänzende datenschutzrechtlich wichtige Angaben bereitzustellen. Dies würde allenfalls einen geringen Mehraufwand aufseiten der Hersteller erfordern, die zur Erfüllung der Pflichten nach dem CRA ohnehin über die Verarbeitungen ihrer Produkte im Bilde sein müssen. Soweit personenbezogene Daten verarbeitet werden, müssten derartige Informationen sonst von Verantwortlichen angefordert werden, um ihrer datenschutzrechtlichen Rechenschaftspflicht nachzukommen. Zu denken wäre hier etwa daran, den verantwortlich Betreibenden von IoT-Geräten Mittel, Anleitungen und Kontaktinformationen zur effektiven und zeitnahen Umsetzung von Betroffenenrechten entlang der Verarbeitungskette an die Hand zu geben.
Weitere Informationen zum Projekt finden Sie unter:
https://www.datenschutzzentrum.de/projekte/unboxingiot/
Kurzlink: https://uldsh.de/tb43-8-3a
8.4 Projekt AnoMed – Kompetenzcluster Anonymisierung für medizinische Anwendungen
Das dreijährige Forschungsprojekt „Anonymisierung für medizinische Anwendungen – AnoMed“ nahm im November 2022 die Arbeit auf. Es wird vom Bundesministerium für Bildung und Forschung sowie der Europäischen Union (NextGenerationEU) als Kompetenzcluster (42. TB, Tz. 8.5) gefördert. Der Fokus liegt auf Pseudonymisierungs- und Anonymisierungsforschung zur Anwendung im Gesundheitsbereich. Im Konsortium von elf Partnern aus Hochschulen, Forschungseinrichtungen und mittelständischen Unternehmen trägt das ULD mit technischer und datenschutzrechtlicher Expertise bei. Das Projekt befasst sich mit vielversprechenden Technologien zum Schutz von Gesundheitsdaten, die insbesondere auf Differential Privacy oder maschinellem Lernen basieren.
Differential Privacy
Bei Differential Privacy handelt es sich um ein Verfahren, mit dem Abfragen aus Datenbanken mit personenbezogenen Daten gezielt verrauscht werden. So lässt sich einerseits eine Nutzbarkeit der Daten, z. B. zum Herausfinden statistischer Werte oder Korrelationen, erhalten und andererseits vermeiden, dass einzelne personenbezogene Datensätze bekannt werden.
Die Gesundheitsforschung ist politisch bedeutend – auch über den medizinischen Bereich hinaus: Mit dem Europäischen Raum für Gesundheitsdaten (European Health Data Space, EHDS) soll eine Blaupause für weitere Datenräume geschaffen werden. Die Europäische Datenstrategie sieht weitreichende Sekundärnutzungen von Daten für Gemeinwohl, Wirtschaft und Verwaltung vor. Die Strategie wird in mehreren Datenräumen in Form von Verordnungen umgesetzt. Oftmals sind die benötigten Daten personenbezogen und teils hochsensibel. Um sie für Datenräume nutzbar zu machen, ist es erforderlich, sie zu anonymisieren oder anderweitig ausreichende Schutzmaßnahmen zu treffen.
Zur technischen Umsetzung von Datenräumen bedarf es eines Brückenschlags zwischen dem teils unterschiedlichen Verständnis von Anonymität der beteiligten Akteure mit technischem, rechtlichem oder wirtschaftlichem Hintergrund. Aus der Arbeit des AnoMed-Projekts heraus wurde bereits eine differenzierte Terminologie vorgestellt (42. TB, Tz. 8.5). Um nun erfolgreich in Europa die minimalen Anforderungen an Anonymisierung zu diskutieren, festzulegen und zu harmonisieren, ist es sinnvoll, verschiedene Arten und Grade von Anonymität ausdrücken zu können. Dies kann Voraussetzung dafür sein, angemessene Anonymisierungsmethoden passend zum jeweiligen Risiko einer Re-Identifizierung auszuwählen.
Aufbauend auf der Terminologie zur Anonymität konnten die verfügbaren Verfahren zur Reduktion des Personenbezugs und zum Erlangen anonymisierter Daten drei wesentlichen Stadien zugeordnet werden. Als Resultat dieser Arbeit ist ein Modell (Zustandsdiagramm) von verschiedenen Arten von Daten mit Variationen bezüglich des Personenbezugs entstanden. Dies wird in Abbildung 5 dargestellt. Gemäß dem Modell können Daten prinzipiell in drei Formen vorliegen:
- direkt identifizierte Information,
- Informationen über Individuen ohne direkt identifizierende Kennungen oder
- in aggregierter Form.
In dieser generalisierenden Darstellung kommt zum Ausdruck, dass der Personenbezug mit bestimmten Transformationen im Allgemeinen abnimmt (nach rechts ausgerichtete graue Pfeile). Das Entfernen direkt identifizierender Merkmale (d. h. Kennungen) wie Namen oder Patientenkennziffern führt zu Datensätzen, die sich immer noch auf Einzelpersonen beziehen, d. h. eine Individualebene darstellen, aber eine Identifizierung nur noch mit geeigneter Zusatzinformation erlauben. Für einen weiter gehenden Schutz könnte der Datenbestand durch Weglassen oder Generalisierung von Informati-
onen so verändert werden, dass eine Verkettung nur noch mit Gruppen von Individuen möglich wäre und diese Gruppen für den gesamten Datenbestand eine gewisse Mindestgröße nicht unterschreiten. Eine weiter reichende Reduktion des Personenbezugs wird erreicht, wenn Merkmale von mehreren Individuen zu einem einzelnen (z. B. statistischen) Wert aggregiert werden. Eine Umkehrtransformation dazu ist bei Offenlegung mehrerer aggregierter Datensätze möglich; dadurch lassen sich – je nach Informationsgehalt der Informationen – alle oder einige der ursprünglichen Daten auf Individualebene rekonstruieren.
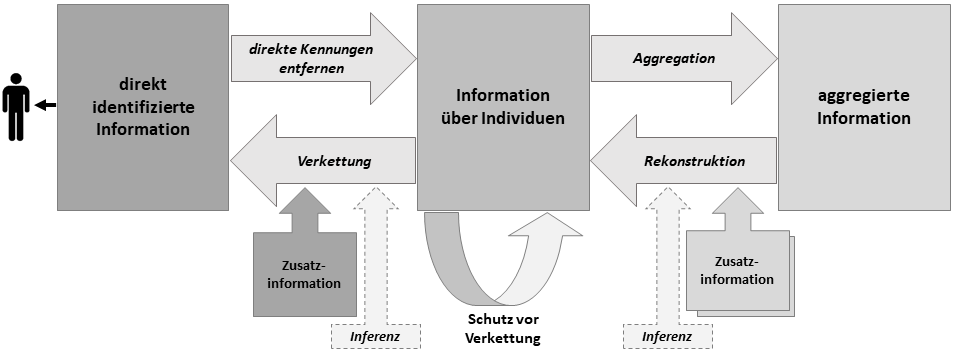
Abb. 5: Zustandsdiagramm über Personenbezug und Anonymisierung
Ein weiteres wichtiges AnoMed-Resultat, das auf dieser Basis ausgearbeitet wurde, ist eine Taxonomie über denkbare Arten von Anonymität. Diese Taxonomie ist sowohl technologieneutral als auch trennscharf.
Projektergebnisse und weitere Informationen sind unter folgendem Link abrufbar:
https://www.datenschutzzentrum.de/projekte/anomed/
Kurzlink: https://uldsh.de/tb43-8-4a
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


