06
Kernpunkte:
- Technische Verantwortlichkeit in verteilten Verfahren
- Personenbezug in KI-Modellen
- Frag‘ für ‘nen Freund
- Rechenschaftspflicht mit System
6 Systemdatenschutz
Die Pflichten des Verantwortlichen erstrecken sich zu einem großen Anteil auf das Treffen geeigneter technischer und organisatorischer Maßnahmen, um das dem Risiko angemessene Schutzniveau zu gewährleisten. Das Recht verlangt eine Gestaltung der Verarbeitung personenbezogener Daten entsprechend der rechtlichen Vorgaben. Aus diesem Grund kommt dem Systemdatenschutz eine besondere Rolle zu.
6.1 Landesebene
6.1.1 Zusammenarbeit mit dem Zentralen IT-Management (ZIT SH)
Wie in den Jahren zuvor war das ULD auch im Jahr 2024 Gast in der Konferenz der IT-Beauftragten (ITBK), in der die IT-Beauftragten der Ressorts zusammen mit dem ZIT über aktuelle und geplante IT-Projekte von zentraler Bedeutung beraten. Durch die Gastrolle in der ITBK, aber auch durch die Teilnahme beim IT-Board in Sankelmark (einem jährlich stattfindenden zweitägigen Workshop der IT-Beauftragten der Ressorts und nachgeordneter Behörden) wird das ULD regelmäßig über viele grundlegende IT-Projekte von zentraler Bedeutung, z. B. im Bereich der Arbeitsplätze (Telefonie, Bürokommunikation, E-Mail, Dateiablage usw.), informiert.
Einen Schwerpunkt bildet im ZIT der zunehmende Einsatz von Open-Source-Produkten. In der Vergangenheit betraf dies vor allem Serverprodukte (etwa Datenbankmanagementsysteme oder Webserver) im „Maschinenraum“ bei Dataport – dies sind Komponenten, die die Nutzerinnen und Nutzer nur indirekt betreffen. Mittlerweile ist man bei der Umstellung auf Open Source in Bereichen angelangt, die für die Nutzerinnen und Nutzer unmittelbar sichtbar sind, etwa die Software der Bürokommunikation („Office“, E-Mail, Webbrowser). Dies erfordert Umstellungen auch bei den Beschäftigten, da die Software anders zu bedienen ist.
Der Einsatz von Open Source ist kein Garant für eine bessere Umsetzung von Informationssicherheit und bedeutet auch nicht zwingend eine Kostenersparnis. Er ermöglicht jedoch in vielen Fällen eine deutliche Verbesserung der Steuerbarkeit, eine größere Unabhängigkeit von Marktbeteiligten und ihren Betriebsmodellen (Stichwort digitale Souveränität, vgl. 42. TB, Tz. 6.2.4) und langfristig die Möglichkeiten einer eigenen Steuerung von IT-Systemen: Im Zweifelsfall ist man nicht den Entscheidungen Dritter ausgeliefert, sondern kann zumindest auf der Ebene der Software frei agieren und alternative Dienstleister beauftragen. Das Land hält sich so Handlungsoptionen offen.
Im Bereich der zentralen Steuerung der Informationssicherheit war das ULD als Gast in der AG Informationssicherheit beteiligt. In dieser Arbeitsgruppe verzahnen sich die zentrale Steuerung der Informationssicherheit des Landes beim ZIT („Chief Information Security Officer“ (CISO)) mit den jeweils Zuständigen in den Ressorts und Behörden. Hier ist erkennbar, dass zusätzliche Ressourcen auf Ebene des ZIT erforderlich sind, um den gestiegenen Anforderungen Rechnung tragen zu können.
Anders als in den Vorjahren gab es im Berichtszeitraum keine formelle Einbindung des ULD in konkrete Verfahren oder in Regelwerke, die eine landesweite Bedeutung haben oder die im Rahmen der Mitbestimmung entstanden sind. Beteiligt war das ULD an einem Projekt im Bereich Veränderungsmanagement zur Umsetzung der Landesdatenstrategie. Weiter erfolgreich fortgesetzt wurde auch die Zusammenarbeit mit anderen IT-Stellen und Datenschutzbeauftragten des Landes, u. a. mit dem Amt für Informationstechnik (AIT), dem Bildungsministerium und dem Sozialministerium sowie einzelnen Bereichen von Ministerien, die eine Datenverarbeitung technisch planen oder umsetzen (siehe auch Tz. 6.1.3).
6.1.2 Zusammenarbeit mit dem ITV.SH
Im Berichtsjahr lag ein Schwerpunkt der Zusammenarbeit mit dem ITV.SH in der Erstellung und Überarbeitung von Dokumenten für das Projekt „SiKoSH“ (siehe auch 42. TB, Tz. 6.1.2): Diese fußen auf Texten und Standards, die ihrerseits Anpassungen unterliegen (z. B. den Grundschutzstandards des BSI, die typischerweise jährlich fortgeschrieben und ergänzt werden) und daher regelmäßig angepasst werden müssen.
SiKoSH
SiKoSH (Sicherheit für Kommunen in Schleswig-Holstein) ist ein kommunales Projekt, das beim Aufbau eines Informationssicherheitsmanagementsystems (ISMS) auf Basis des IT-Grundschutzes des BSI (BSI = Bundesamt für Sicherheit in der Informationstechnik) unterstützt.
Als Grundlage wird das BSI-Grundschutzprofil „Basisabsicherung Kommunalverwaltung“ verwendet. Ein solches Grundschutzprofil stellt aus den zahlreichen Anforderungen des BSI-Grundschutzes diejenigen zusammen, die für einen bestimmten Anwenderkreis relevant sind – hier eben für den Bereich der Kommunen.
In diese Anpassungen sowie in erstellte Musterdokumente gehen auch Ergebnisse aus unserer Beratung und Aufsichtspraxis ein, beispielsweise in Form von Hinweisen und Blaupausen für Musterrichtlinien und Regelungen zum Umgang mit Sicherheitsvorfällen, die Datenschutzkomponenten haben. Denn nicht alle Personen, die im Bereich des Informationssicherheitsmanagements tätig sind, denken an mögliche Meldepflichten gemäß Artikel 33 DSGVO und verwandte Obliegenheiten. Es müssen in der Praxis Regelungen geschaffen werden, die den Informationsfluss innerhalb der Behörden steuern – nicht zuletzt im Hinblick auf die Frist von 72 Stunden bei der Meldung von Datenschutzverletzungen gegenüber der Aufsichtsbehörde.
Ein weiterer Berührungspunkt zwischen dem ITV.SH und dem ULD ergab sich zusammen mit dem Landesarchiv bei einem Projekt zur kommunalen Archivierung: Das Landesarchiv arbeitet in einem Verbund mit anderen (Landes-) Archiven zusammen, um digitale Medien zu archivieren. Hierbei bestehen ganz neue Anforderungen, etwa im Hinblick auf die Konvertierung typischer Dateiformate in archivfähige Formate für die Langzeitspeicherung. Proprietäre Dateiformate einzelner Softwareanbieter, so bekannt und so verbreitet sie auch heutzutage sein mögen, sind dafür nicht geeignet.
Auch die Speichertechnologie ändert sich ständig – man denke etwa an Tonträger, die allein in den letzten 40 Jahren einen Wandel von Vinylplatte über Kompaktkassetten und CDs bis hin zu heute vorherrschenden Streamingdiensten gemacht haben. Ebenso spielen bauliche Aspekte eine Rolle: Rechenzentren zur Langzeitspeicherung digitalen Archivmaterials müssen anders gestaltet sein als solche zur Lagerung von Papierdokumenten.
Mit allen diesen Fragen sind letztlich alle Archive befasst, um die zukünftig ausschließlich digital vorliegenden Verwaltungsdokumente archivieren zu können. Hier setzt das Projekt des Landesarchivs an, über den ITV.SH als zentrale Stelle interessierten Kommunalarchiven die technische Plattform, die vom Landesarchiv genutzt wird, ebenfalls zur Verfügung zu stellen.
Aus Datenschutzsicht ist hierbei relevant, welche Vertrags- und Weisungsverhältnisse bestehen. Aus technischer Sicht ist bedeutsam, dass der Zugriff auf digitale Archivmaterialien in Bezug auf Sicherheit und Kontrolle keine Einbußen gegenüber der Papierwelt aufweist.
6.1.3 Technische Verantwortlichkeit in verteilten Verfahren
Viele Beratungsanfragen, auch im regelmäßigen Austausch mit IT- und Datenschutzbeauftragten der Ressorts, betreffen die Umsetzung von Verfahren, die auf landesweit oder bundesweit verfügbarer Software basieren – oft in Verbindung mit einer Auftragsverarbeitung beim Anbieter. In diesen Fällen gilt es zunächst zu klären, ob solche Verfahren eigenverantwortlich oder in einem Verbund mit anderen Stellen betrieben werden sollen. Davon hängt ab, welche Verantwortlichkeiten bestehen. Bei Verfahren im Verbund gibt es häufig nur eine Stelle, die gegenüber einem Auftragsverarbeiter als weisungsberechtigt auftritt. Hier stellen sich Fragen der gemeinsamen Verantwortlichkeit.
Bei der Beurteilung solcher Verfahren ist auch zu prüfen, ob und welche bereits bestehenden rechtlichen Bewertungen, Funktionalitäten mit Datenschutzbezug sowie technischen Konfigurationen von anderen Teilnehmenden aus dem Verbund übernommen werden können. Meist gibt es Unterschiede, etwa aufgrund landesrechtlicher Regelungen oder der Verwaltungsorganisation, die eine differenzierte Betrachtung notwendig machen. Das betrifft beispielsweise Einsatzszenarien bei Produkten oder Verfahren, die aus anderen Bundesländern übernommen oder auch gemeinsam mit diesen betrieben werden sollen. Hier muss überprüft werden, welche Anpassungen erforderlich sind.
Ein typischer Bereich ist der Bildungsbereich: Zum einen besteht hier die rechtliche Hoheit der Länder, zum anderen unterscheiden sich Organisationsform und Zuständigkeiten zwischen den Ländern oder sogar regional. Denn in Schleswig-Holstein liegt die Verantwortung etwa für Schulgebäude (relevant für technische Fragen wie etwa WLAN-Bereitstellung und Übergang in Landesnetze) und Lernmittel (z. B. Lizenzen für Lernsoftware) in kommunaler Hand, während die Fragen des Schulbetriebs Landessache sind. So ist der Schulbetrieb meist in örtlicher Verantwortung (Schulleitungen) organisiert, es gibt aber auch landesweite Verfahren, etwa die Bereitstellung von Laptops für Lehrkräfte, Angebote des IQSH (Institut für Qualitätsentwicklung an Schulen Schleswig-Holstein) oder eine landesweite Schulverwaltungssoftware.
Ähnliches gilt für Infrastrukturen wie z. B. Kommunikations- und Datenaustauschplattformen, die gemeinsam von Land und Kommunen genutzt werden sollen, etwa im Gesundheitsbereich. Wichtig ist in jedem Fall die Klärung der Verantwortlichkeiten und Zuständigkeiten von Anfang an, um damit auch Klarheit über Rechtsgrundlagen und Pflichten der Verantwortlichen – einschließlich der Auswahl und Implementierung geeigneter und wirksamer technischer und organisatorischer Maßnahmen – zu erhalten.
Was ist zu tun?
Auch Verfahren, die in anderen Bundesländern oder bei anderen Verantwortlichen im Einsatz sind, lassen sich datenschutzrechtlich nicht immer 1:1 auf die Situation in Schleswig-Holstein übertragen. Eine genaue Betrachtung der Verantwortlichkeiten ist gerade bei gemeinsamen Verfahren erforderlich.
6.2 Deutschlandweite und internationale Zusammenarbeit der Datenschutzbeauftragten
6.2.1 Neues aus dem AK Technik
Der Arbeitskreis (AK) Technik der Datenschutzkonferenz (DSK) beschäftigt sich mit technischen Fragestellungen, die in der Datenschutzberatung und Aufsichtspraxis aufgeworfen werden. Neben den Datenschutzaufsichtsbehörden des Bundes und der Länder sind auch Vertreter des Datenschutzes aus den Kirchen und dem Rundfunk sowie Datenschutzaufsichtsbehörden im deutschsprachigen Ausland beteiligt. Neu in diesem Kreis ist die Bayerische Landeszentrale für neue Medien.
Schwerpunkte in diesem Jahr waren neben dem Standard-Datenschutzmodell (SDM, Tz. 6.2.2) Beiträge zum Einsatz biometrischer Verfahren auf Flughäfen (Tz. 6.2.3), zu Leitlinien für Anonymisierung und Pseudonymisierung (Tz. 6.2.4) sowie Zuarbeiten im Bereich der künstlichen Intelligenz (Tz. 6.2.5, Tz. 6.2.6). Hier besteht eine enge Kooperation insbesondere mit Task Forces der DSK und mit der Technology Expert Subgroup (TECH). Die TECH ist ein Fachgremium des Europäischen Datenschutzausschusses (EDSA), das sich mit technischen Fragestellungen auf europäischer Ebene befasst – sozusagen das Spiegelbild des AK Technik auf der europäischen Ebene. Die deutschen Diskussionsbeiträge in diesem Ausschuss stammen u. a. aus dem AK Technik, die Diskussionen werden mit dem AK Technik rückgekoppelt.
Dies ist wichtig, da die Dokumente des EDSA, die auf den Arbeiten seiner Fachausschüsse beruht, in Form von Leitlinien und Stellungnahmen europaweite Bedeutung haben. Sie sind für die Datenschutzpraxis in Deutschland zu beachten und haben teilweise bindende Wirkung.
Ein größeres Thema, dessen sich der AK Technik angenommen hat, ist die Betrachtung von Datenschutzaspekten im 6G-Mobilfunkstandard. Relevant dabei ist, dass aufgrund der verwendeten Frequenzen nicht nur eine Signalübertragung möglich ist, sondern auch eine Sensorik, etwa durch Analyse von Reflexionsmustern ähnlich wie beim Radar. Bei der Standardisierung geht es darum, dass diese Aspekte nicht bereits auf technischer Ebene vermischt werden. Es sollten beispielsweise bei einer Kommunikation mittels 6G nicht automatisiert Geschwindigkeit und Bewegung sämtlicher dazwischenliegender Objekte erfasst werden, sondern Anwendende (z. B. von Mobiltelefonen) müssen eine solche Sensorik steuern können. Voraussetzung dafür ist aber, dass in den technischen Protokollen eine Steuerungsmöglichkeit überhaupt vorgesehen ist.
6.2.2 Standard-Datenschutzmodell – ein Update
Im Jahr 2024 haben die Aktivitäten zur Weiterentwicklung des Standard-Datenschutzmodells (SDM) wieder Fahrt aufgenommen. Dieses Jahr war zum einen davon geprägt, die Bedeutung des SDM für die DSK zu klären. Zum zweiten wurde die SDM-Methodik um das Kapitel zu Betriebsmitteln ergänzt. Dies mündete in der Version 3.1 des SDM.
Das SDM hat mehrere Schwächen, die länger schon bekannt sind und behoben werden müssen. Unter anderem mangelt es den Bausteinen an Bezügen zum sogenannten SDM-Würfel (vgl. 41. TB, Tz. 6.2.2), der die einzelnen Verarbeitungsschritte (wie Erheben, Bearbeiten, Nutzen, Löschen) zu den Gewährleistungszielen des Datenschutzes in Beziehung setzt. Einige der online verfügbaren SDM-Bausteine stammen aus den Frühzeiten der Inkraftsetzung der DSGVO. Darin konnten noch keine Bezüge zum SDM-Würfel hergestellt worden sein, was aber zur Verortung einer Maßnahme im gesamten Gefüge einer Verarbeitung sehr hilfreich wäre.
Noch unbefriedigend ist auch, dass nach wie vor Bausteine für zentrale Aspekte fehlen, darunter die wichtigen kryptografischen Themen wie Verschlüsselung und Integritätsschutz. Im SDM wird deshalb übergangsweise auf die Maßnahmenkataloge zum IT-Grundschutz des BSI verwiesen. Diese beschreiben gut die technischen Aspekte der Kryptografie. Benötigt werden aber auch Konzepte für eine datenschutzrechtlich durchdachte Umsetzung, etwa beim Schlüsselmanagement, der sicheren Trennung (insbesondere von Verarbeitungen verschiedener Verantwortlicher in einer Infrastruktur) oder der Abschottung von Protokolldaten, gegebenenfalls auch von der eigenen Administration.
Wir erhalten zum SDM öfter die Rückmeldung, dass es beim Einstieg und für kleine Organisationen zu kompliziert sei. Um dies zu vereinfachen, wollen wir Lese- und Einstiegshilfen entwickeln.
Insgesamt ist es der DSK ein Anliegen, das SDM als Standardmethode für das Prüfen und Beraten von Verarbeitungen personenbezogener Daten noch handhabbarer zu machen. Mit diesem Ziel beauftragte die DSK die Unterarbeitsgruppe SDM (UAG SDM), insbesondere folgende Themen zu bearbeiten:
- Überarbeitung des generischen Maßnahmenkatalogs: jede Maßnahme präziser als bislang gegeneinander konturieren und dann Bezüge zum SDM-Würfel herstellen,
- Überarbeitung der Strukturierung der Bausteine und Bezugnahme auf das Methodikniveau des SDM-V3.1,
- einen vorhandenen Baustein entsprechend aktualisieren, der als Muster für die Arbeiten an weiteren Bausteinen dient; hierbei ist inzwischen die Wahl auf den Baustein „Protokollieren“ gefallen,
- eine SDM-Special-Edition entwickeln, die insbesondere Neulingen dabei hilft, leichter einen Einstieg zu finden,
- die Schnittstelle zum IT-Grundschutz des BSI klarer herausarbeiten,
- Erarbeitung eines Leitfadens für die Anbindung von Autorinnen und Autoren, die nicht im datenschutzbehördlichen Kontext beschäftigt sind.
Neu in der Version 3.1 des SDM ist das Kapitel „D2.2 Mittel einer Verarbeitung“ (Satz 39 f.). In diesem Kapitel werden zunächst „Mittel der Verarbeitung“ von den „Betriebsmitteln“ unterschieden. Zu den Mitteln der Verarbeitung (im Sinne der DSGVO) gehören „[...] insbesondere die einschlägige Organisation der verarbeitenden Stelle (Aufbau- und Ablauforganisation), die Unterstützung durch Systeme und Dienste (Betriebsmittel) sowie die konkrete Festlegung des verarbeiteten Datenbestands (Datenmodelle und Datenbasis)“.
Für das SDM sind dabei die technischen Betriebsmittel zentral. Dabei wird unterschieden zwischen „unmittelbar unterstützenden“ und „mittelbar unterstützenden“ Betriebsmitteln. Zu den als unmittelbar bezeichneten Betriebsmitteln zählen beispielsweise ein IT-gestützter Arbeitsplatz oder ein E-Mail-System. Zu den mittelbaren Betriebsmitteln zählen z. B. Maßnahmen im Rahmen einer Verarbeitung, die das Risiko einer Verarbeitung mindern, wie ein Back-up-System oder ein Antischadsoftwaresystem.
Die Definition von Betriebsmitteln ist wichtig, um die Verfahren sauber strukturieren zu können und Doppelbetrachtungen von Komponenten zu vermeiden: Betriebsmittel können miteinander teilweise hierarchisch verbunden und geeignet sein, als mehrfach genutzte Betriebsmittel verschiedene Verarbeitungstätigkeiten zu unterstützen (wie z. B. IT-gestützter Arbeitsplatz).
Das SDM-V3.1 ist unter dem folgenden Link abrufbar:
https://www.datenschutzzentrum.de/uploads/sdm/SDM-Methode_V3_1.pdf
Kurzlink: https://uldsh.de/tb43-6-2-2a
6.2.3 EDSA-Guidelines zur Gesichtserkennung am Flughafen
Im Zuge der Mitarbeit in der Technology Expert Subgroup des Europäischen Datenschutzausschusses (EDSA) beteiligte sich das ULD an der Erstellung einer Stellungnahme zur Nutzung von Gesichtserkennungstechnologien an Flughäfen. Die Stellungnahme wurde auf Anfrage der französischen Datenschutzbehörde erstellt und beschäftigt sich mit der zunehmenden Implementierung biometrischer Systeme zur Optimierung von Passagierkontrollen.
Die Stellungnahme greift dabei ein hochaktuelles Thema auf: Flughafenbetreiber und Luftfahrtunternehmen stehen vor der Herausforderung, steigende Passagierzahlen bei gleichzeitig erhöhten Sicherheitsanforderungen zu bewältigen. Mit der Nutzung biometrischer Verfahren sollen eine effizientere Prozessgestaltung und verbesserte Sicherheitskontrollen möglich sein. Gleichzeitig bergen diese Technologien erhebliche datenschutzrechtliche Risiken. Eine klare rechtliche Einordnung dieser Verfahren war daher dringend erforderlich.
In seiner Bewertung kam der EDSA zu dem Schluss, dass nur zwei Arten für die Speicherung der biometrischen Daten mit den Grundsätzen der Integrität, Vertraulichkeit und Datensicherheit vereinbar sind: die Speicherung der biometrischen Daten ausschließlich beim Passagier selbst oder – alternativ – verschlüsselt in einer zentralen Datenbank, bei der sich der Verschlüsselungsschlüssel allein in der Hand des Passagiers befindet. Eine zentrale Speicherung ohne Kontrolle durch die betroffene Person wird in der Stellungnahme als unvereinbar mit den Anforderungen des Datenschutzes eingestuft.
Für deutsche Aufsichtsbehörden und Flughafenbetreiber liefert die Stellungnahme wichtige Klarstellungen zur datenschutzkonformen Ausgestaltung biometrischer Systeme. Insbesondere wurde festgehalten, dass eine biometrische Verifikation nur dann erfolgen darf, wenn auch eine gesetzliche Pflicht zur Identitätsprüfung besteht. Die Verarbeitung biometrischer Daten setzt zudem in jedem Fall eine aktive Einwilligung der Passagiere voraus.
Die Stellungnahme 11/2024 zum Einsatz von Gesichtserkennung zur Straffung der Fluggastströme (Vereinbarkeit mit Artikel 5 Absatz 1 Buchstaben e und f, Artikel 25 und Artikel 32 DSGVO) ist unter dem folgenden Link abrufbar:
https://www.edpb.europa.eu/our-work-tools/our-documents/opinion-board-art-64/opinion-112024-use-facial-recognition-streamline_de
Kurzlink: https://uldsh.de/tb43-6-2-3a
6.2.4 EDSA-Guidelines zu Anonymisierung und Pseudonymisierung
Die Frage, ob bestimmte Daten „personenbezogene Daten“ im Sinne der DSGVO sind, ist von großer Bedeutung – schließlich entscheidet sie darüber, ob der Anwendungsbereich der DSGVO bzw. der Datenschutzgesetze eröffnet ist. Für nicht personenbezogene Daten ist die DSGVO nicht anzuwenden. Zwar gibt es auch für solche Daten Regelungen – man denke an Geheimschutz oder Regelungen zu Betriebs- und Geschäftsgeheimnissen –, doch sind diese nicht datenschutzrechtlicher Natur.
Ob Daten personenbezogen im Sinne der DSGVO sind, ist nicht immer einfach festzustellen. Laut Definition in Art. 4 Nr. 1 DSGVO geht es um „alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person [...] beziehen“. Bei Namen und Anschriften, E‑Mail-Adressen, Identifikationsnummern usw. besteht daran kein Zweifel.
Aber wie ist das mit statistischen Daten oder mit Daten, die das Ergebnis einer Anonymisierung personenbezogener Daten sind? Ein einzelnes Datum wie „Mann, 43 Jahre alt“ wird man kaum als personenbezogen oder -beziehbar ansehen. Bei der Angabe „Frau, ehemalige Bundeskanzlerin“ wird man hingegen auch ohne Angabe eines Namens wissen, wer gemeint ist. Spannend ist wie immer der Zwischenbereich: Wie sieht es mit „Frau, ehemalige Bundesministerin“ oder „Mann, ehemaliger Ministerpräsident eines Bundeslandes“ aus? Hier werden wohl noch Zusatzinformationen (z. B. zum Zeitpunkt) notwendig sein, um Betroffene eindeutig zu bestimmen.
Für die rechtliche Beurteilung ist relevant, wer über dieses Zusatzwissen verfügt und für wen es realistischerweise zugänglich ist, aber auch wie groß der Aufwand für eine Identifizierung einer betroffenen Person ist. Hinweise finden sich im Erwägungsgrund 26 der DSGVO.
Aus dem Erwägungsgrund 26 der DSGVO
[…] Um festzustellen, ob eine natürliche Person identifizierbar ist, sollten alle Mittel berücksichtigt werden, die von dem Verantwortlichen oder einer anderen Person nach allgemeinem Ermessen wahrscheinlich genutzt werden, um die natürliche Person direkt oder indirekt zu identifizieren, wie beispielsweise das Aussondern. Bei der Feststellung, ob Mittel nach allgemeinem Ermessen wahrscheinlich zur Identifizierung der natürlichen Person genutzt werden, sollten alle objektiven Faktoren, wie die Kosten der Identifizierung und der dafür erforderliche Zeitaufwand, herangezogen werden, wobei die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologische Entwicklungen zu berücksichtigen sind. […]
Im konkreten Einzelfall ist es strittig, was es genau bedeutet, dass „alle Mittel berücksichtigt werden, die von dem Verantwortlichen oder einer anderen Person nach allgemeinem Ermessen wahrscheinlich genutzt werden, um die natürliche Person direkt oder indirekt zu identifizieren, wie beispielsweise das Aussondern“; es gibt bereits mehrere Urteile des Europäischen Gerichtshofs, in dem dieser Aspekt angesprochen wird.
Dass das Wegstreichen eines Namens aus einem Datensatz zum Anonymisieren nicht ausreicht, zeigt das oben genannte Beispiel des Berufs „Bundeskanzlerin“. Aber wie kann man feststellen, ob Daten anonym sind oder eine Anonymisierung erfolgreich war? Kann man für ein effektives Anonymisieren eine Anleitung oder eine Checkliste erstellen?
Zahlreiche wissenschaftliche Veröffentlichungen in diesem Bereich zeigen, dass die Antwort nicht ganz einfach ist: Für viele vorgeschlagene Anonymisierungsverfahren gibt es Untersuchungen über ihre Schwächen. Dies erinnert an das Ringen um die besten Verschlüsselungsverfahren – neue Vorschläge werden auf den Prüfstand gestellt und müssen sich beweisen.
Mit diesen Fragen beschäftigt sich seit mehreren Jahren auch der EDSA und erstellt gerade zwei Dokumente mit Leitlinien (Guidelines), an denen auch wir beteiligt sind. Diese Leitlinien sind in die Bereiche der Pseudonymisierung und der Anonymisierung aufgeteilt.
Hier geht Sorgfalt vor Schnelligkeit, denn Fehler können schwerwiegend sein: Werden (vermeintlich) anonyme Daten veröffentlicht, sind sie für alle zugänglich. Stellt sich später heraus, dass betroffene Personen dennoch (re-)identifiziert werden können, lässt sich die erfolgte Veröffentlichung nicht wieder rückgängig machen – und ein entstandener Schaden kann möglicherweise irreversibel sein. Mit derartigen Fragen beschäftigen wir uns auch im vom BMBF geförderten Projekt AnoMed (Tz. 8.4).
Anfang 2025 wurde vor Drucklegung dieses Berichts die Konsultationsfassung der Guidelines 01/2025 on Pseudonymisation fertiggestellt, die unter dem folgenden Link zur Verfügung steht:
https://www.edpb.europa.eu/our-work-tools/documents/public-consultations/2025/guidelines-012025-pseudonymisation_de
Kurzlink: https://uldsh.de/tb43-6-2-4a
Nach Ablauf der öffentlichen Konsultation wird eine überarbeitete Fassung dieser Leitlinien zur Pseudonymisierung auf der Website des EDSA auf Englisch und in den anderen Sprachen der Mitgliedstaaten abrufbar sein. Mit der Fertigstellung der Leitlinien zur Anonymisierung ist im Jahr 2025 zu rechnen.
Was ist zu tun?
Sollen Daten anonymisiert veröffentlicht werden, sollte man sich sehr sicher sein, dass sie wirklich anonym sind. Die derzeit in Arbeit befindlichen Guidelines des EDSA werden dann eine Hilfe bieten.
6.2.5 Die KI zaubert nicht – Diskussion zu Personenbezug in KI-Modellen
Mit den zunehmenden konkreten Einsatzmöglichkeiten von KI-Systemen und insbesondere großen Sprachmodellen haben sich Aufsichtsbehörden in Deutschland und Europa intensiv mit der datenschutzrechtlichen Einordnung von solchen Large Language Models (LLMs) befasst. Ein besonderer Fokus lag ab Frühsommer 2024 dabei auf der grundlegenden Frage, ob in trainierten LLMs personenbezogene Daten im Sinne der DSGVO verbleiben und somit ein Personenbezug gegeben ist.
Nach eingehender Analyse vertritt das ULD die Position, dass ein Personenbezug in LLMs jedenfalls nicht pauschal ausgeschlossen werden kann. Bei Modellen, die mit personenbezogenen Daten trainiert wurden, ist nach aktuellem Stand der Wissenschaft davon auszugehen, dass Informationen darüber im trainierten Modell verbleiben. Diese Einschätzung stützt sich insbesondere auf die komplexe Beschaffenheit der Informationsrepräsentation in diesen Systemen sowie die nachgewiesenen Möglichkeiten zur Extraktion (d. h. dem Auslesen oder Abrufen) von Trainingsdaten.
Auch zusätzliche Schutzmaßnahmen, etwa durch Alignment-Techniken (Ausrichtung eines KI-Modells an vorgegebene Regeln und Direktiven), können nach bisherigen Erkenntnissen nicht zuverlässig verhindern, dass personenbezogene Daten nach dem Training verarbeitet oder ausgegeben werden. Dieser Auffassung entspricht auch die im Dezember veröffentlichte EDSA-Stellungnahme zu personenbezogenen Daten in KI-Modellen (Tz. 6.2.6).
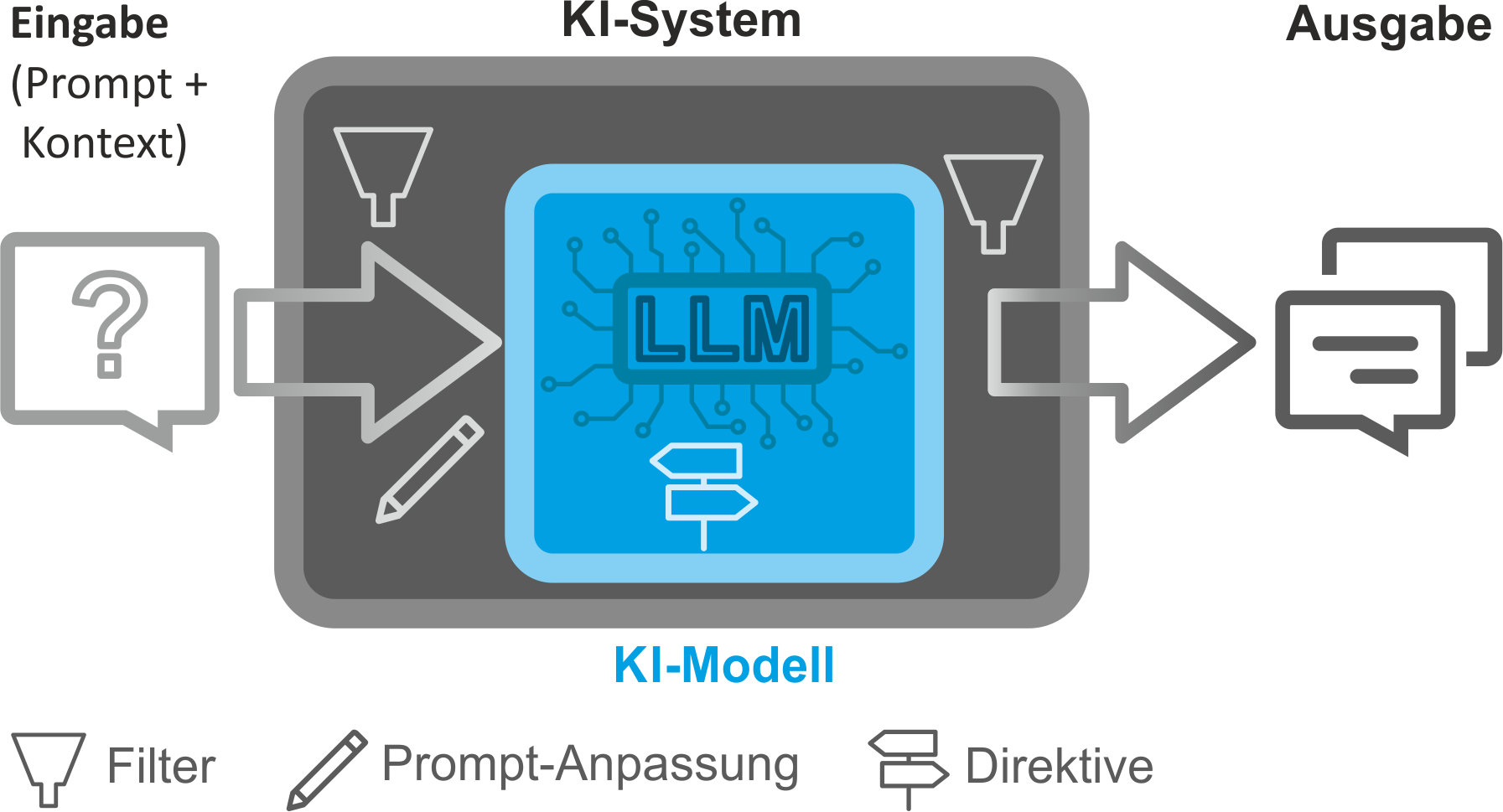
Abb 3: Das KI-Modell eingebettet in ein KI-System mit Ein-und Ausgaben
Aus dieser Bewertung folgt u. a.: Sowohl der Einsatz als auch die Weitergabe von LLMs müssen unter Berücksichtigung der datenschutzrechtlichen Vorgaben erfolgen – selbst wenn der beabsichtigte Einsatz ohne Personenbezug auskommen soll. Da KI-Modelle eingebettet in KI-Systeme betrieben werden (siehe Abb. 3), können Filter und andere Maßnahmen ergriffen werden, um die datenschutzrechtlichen Risiken zu verringern, etwaige negative Auswirkungen auszuschließen oder zumindest abzumildern und gegebenenfalls einen datenschutzkonformen Einsatz zu ermöglichen.
Eine besondere Herausforderung stellt für Verantwortliche in jedem Fall die erforderliche Risikoeinschätzung dar, da wesentliche Informationen über Trainingsdaten, Optimierungsziele und interne Prozesse der Modelle bzw. Systeme häufig nur den Anbietern vorliegen. Der Verantwortliche, der KI-Modelle oder KI-Systeme einsetzt, bleibt aber datenschutzrechtlich dafür verantwortlich.
6.2.6 Formelles Artikel-64er-Verfahren zu KI – die Antworten des EDSA
Im September 2024 hat sich die irische Datenschutzbehörde an den EDSA gewandt und im formellen Stellungnahmeverfahren nach Art. 64 Abs. 2 DSGVO um die Beantwortung von einigen wichtigen Fragestellungen zur KI-Entwicklung gebeten. Diese wurde in den Fachausschüssen des EDSA bis Dezember 2024 entwickelt und veröffentlicht.
Die Stellungnahme zum Einsatz personenbezogener Daten bei der Entwicklung und dem Betrieb von KI-Modellen gibt Hinweise zu grundlegenden Datenschutzaspekten und bietet damit einen Rahmen für eine datenschutzkonforme Umsetzung von KI-Anwendungen. Sie betont, dass Datenschutz und verantwortungsvolle KI-Innovation keine Gegensätze darstellen. Die Stellungnahme nennt konkrete Kriterien, unter denen KI-Modelle datenschutzkonform entwickelt und betrieben werden können (zum Unterschied zwischen KI-Systemen und KI-Modellen siehe Tz. 6.2.5 sowie Abb. 3). Der EDSA befasst sich dabei mit drei zentralen Fragestellungen: der Anonymität von KI-Modellen, ob und wie berechtigte Interessen als Rechtsgrundlage herangezogen werden können sowie den Auswirkungen rechtswidrig verarbeiteter personenbezogener Daten bei der Modellentwicklung. Die Stellungnahme schafft damit Rechtssicherheit für die Entwicklung und Anwendung von KI – mit Blick auf den notwendigen Schutz personenbezogener Daten.
Von besonderer praktischer Bedeutung sind die vom EDSA entwickelten Prüfkriterien zur Bewertung der Anonymität von KI-Modellen sowie der vorgeschlagene dreistufige Test zur Prüfung berechtigter Interessen. Für die Beurteilung berechtigter Interessen werden dabei wichtige Aspekte wie die Erwartungshaltung der betroffenen Personen, der Kontext der Datenerhebung und mögliche risikoeindämmende Maßnahmen berücksichtigt. Bezüglich der Anonymität von KI-Modellen stellt der EDSA klar, dass diese im Einzelfall zu prüfen ist und sowohl die Möglichkeit der Identifizierung betroffener Personen als auch die Extraktion personenbezogener Daten durch Abfragen zu berücksichtigen sind.
Von grundsätzlicher Bedeutung ist zudem die Klarstellung des EDSA zu den Folgen einer rechtswidrigen Verarbeitung personenbezogener Daten bei der Entwicklung von KI-Modellen. Die Stellungnahme macht deutlich, dass sich die Rechtswidrigkeit des Trainings auch auf den späteren Einsatz des Modells auswirken kann – das ist von Fall zu Fall zu prüfen. Eine Ausnahme gilt nur dann, wenn das Modell nachweislich wirksam anonymisiert wurde. Diese Position unterstreicht die Notwendigkeit, bereits bei der Entwicklung von KI-Modellen auf eine rechtskonforme Datenverarbeitung zu achten, um keine (möglicherweise unüberwindbaren) Hürden für einen späteren Einsatz zu schaffen.
Die differenzierenden Kriterien ermöglichen eine sachgerechte Einzelfallbetrachtung und tragen der schnellen technologischen Entwicklung im KI-Bereich Rechnung. Die Stellungnahme verdeutlicht damit, dass die Datenschutzgrundsätze der DSGVO einen geeigneten und flexiblen Rahmen für die verantwortungsvolle Entwicklung innovativer KI-Systeme bieten.
Die Stellungnahme „Opinion 28/2024 on certain data protection aspects related to the processing of personal data in the context of AI models“ ist auf Englisch unter dem folgenden Link abrufbar:
https://www.edpb.europa.eu/our-work-tools/our-documents/opinion-board-art-64/opinion-282024-certain-data-protection-aspects_en
Kurzlink: https://uldsh.de/tb43-6-2-6a
6.3 Ausgewählte Ergebnisse aus Prüfungen, Beratungen und Meldungen nach Artikel 33 DSGVO
6.3.1 Typische Beispiele und Erkenntnisse aus Datenpannenmeldungen
Alle Jahre wieder – Meldungen über Datenpannen (genauer: Verletzungen des Schutzes personenbezogener Daten) beschäftigen uns weiterhin in großem Umfang. Auffällig ist, dass von einigen Organisationen vergleichsweise häufig Meldungen eintreffen, von anderen gar nicht. Dies lässt mehrere Schlüsse zu: Entweder sind diese Organisationen eher schlecht im Hinblick auf Datenschutz und Datensicherheit aufgestellt. Oder sie sind – im Gegensatz zu anderen Organisationen – besonders sensibel und haben funktionierende Meldeketten für Datenschutzverstöße. Oder es liegt schlicht an der Größe einer Organisation: Sind sehr viele Personen mit der Verarbeitung personenbezogener Daten betraut, kommt es mit einer größeren Wahrscheinlichkeit zu Datenpannen.
Auch die Qualität der Aufarbeitung der Vorfälle schwankt stark: Ein Teil der Meldungen beschreibt lediglich das aufgetretene Problem (z. B. einen unbefugten Zugriff auf ein E-Mail-Postfach und anschließendem Versand von Spam), was von unserer Seite oft ein mehrfaches Nachfragen nach Ursachen und geplanten Abhilfemaßnahmen erfordert – denn dies gehört zu einer korrekten Bearbeitung eines Artikel-33-Vorfalls. Andere Meldungen sind deutlich präziser; und auch wenn der Sachverhalt oder die genauen Ursachen zum Zeitpunkt der initialen Meldung noch nicht bekannt ist, wird diese Meldung eigeninitiativ ergänzt, der Fall wird aufgearbeitet, und erläuternde Unterlagen werden selbstständig nachgereicht.
Ein Schwerpunkt der Meldungen betrifft „kleinere“ Verletzungen des Schutzes personenbezogener Daten, die beispielsweise auf der Verwechslung von Unterlagen oder Dateien zweier betroffener Personen beruhen. In diesen Fällen gibt es kaum technische Gegenmaßnahmen; stattdessen ist erhöhte Aufmerksamkeit und doppelte Kontrolle angesagt. Auch Änderungen von Prozessen können helfen, um die gebotene Sorgfalt zu erreichen.
Weiterhin stark vertreten sind Angriffe durch Schadsoftware, etwa Verschlüsselungstrojaner. Auch wenn nicht klar ist, ob Daten wirklich abgeflossen und somit in die Hände Dritter gelangt sind, steht diese Möglichkeit immer im Raum: Wer ein Computersystem so manipulieren kann, dass Schadcode aus dem Internet heruntergeladen wird und Datenspeicher verschlüsselt werden, kann auch Daten über das Internet verschicken.
Dieses Szenario ist auch nicht unwahrscheinlich: Hat man eine funktionierende und aktuelle Datensicherung, so verliert ein Verschlüsselungstrojaner seinen Schrecken. Statt ein „Lösegeld“ für die Entschlüsselung zu zahlen, stellen Verantwortliche die Daten aus der Datensicherung wieder her. Angreifer reagieren darauf mit einer Doppelstrategie, indem Daten nicht nur verschlüsselt, sondern gleichzeitig auch kopiert werden – eine sogenannte Exfiltration. Zahlt dann ein Opfer nicht das verlangte Lösegeld, weil es dank Datensicherung nicht auf die Entschlüsselung angewiesen ist, so kann man es mit einer zweiten Drohung, der Veröffentlichung der exfiltrierten Daten, erpressen.
Schließlich steigt die Zahl der Angriffe auf E‑Mail-Konten, deren Zugangsdaten mittels Phishing erbeutet werden: Die Nutzenden werden verleitet, ihre Zugangsdaten einem Angreifer zur Verfügung zu stellen, z. B. über nachgemachte Log-in-Fenster oder gefälschte Webseiten. Dazu reicht es beispielsweise, einem Opfer eine E-Mail mit einem Link zu einer Webseite (unter der Kontrolle des Angreifers) zuzusenden und zur Eingabe des Passworts aufzufordern. Konnte man früher solche E-Mails vergleichsweise leicht an fehlerhaften Formulierungen und logischen Ungereimtheiten erkennen, lassen sich heutzutage die Angreifer unterstützen und solche E-Mails mittels KI passgenau für das Zielpublikum entwerfen. Die „erbeuteten“ Zugangsdaten werden dann verwendet, um auf E-Mail-Konten zuzugreifen. Im harmlosen Fall werden die Konten zum Versand von Spam genutzt, aber es besteht auch die Gefahr, lesend auf sämtliche gespeicherte E‑Mails und Adressbücher zuzugreifen oder unbefugt E-Mails im Namen des rechtmäßigen Eigentümers zu versenden. Ein beliebtes Beispiel sind E-Mails der (vermeintlichen) Geschäftsleitung, die bei der Buchhaltung eine Zahlung auf ein Auslandskonto beauftragen möchte. Die E-Mail ist dann „echt“, wurde aber nicht von der Geschäftsleitung, sondern vom Angreifer verfasst. Sie stammt auch vom korrekten E-Mail-Server und ist daher technisch nur sehr schwer oder gar nicht von einer E-Mail des rechtmäßigen Eigentümers zu unterscheiden.
Angriffe dieser Art nehmen zu, weil der Zugang zu dienstlicher oder geschäftlicher E-Mail anders als früher nicht mehr das Betreten eines Dienstgebäudes oder Büros und die Nutzung der dortigen Computer voraussetzt: Viele E-Mail-Systeme sind nämlich mittlerweile ohne besondere Sicherungsmaßnahmen direkt über das Internet mittels Nutzernamen und Passwort und mit jeglicher Hardware zugänglich. Ein Angreifer, der solche Zugangsdaten erbeutet, kann dann ebenso über das Internet auf das E-Mail-Konto zugreifen.
Als Gegenmaßnahme empfiehlt sich in diesem Fall, den Zugang zu E-Mail-Systemen an einen zweiten Faktor zu koppeln, der zusätzlich zu Nutzername und Passwort wirkt und sich möglichst schwer kopieren oder entwenden lässt. Ein Beispiel hierfür ist eine zusätzliche Zwei-Faktor-Authentifizierung, die einen unbefugten Zugang erschwert. Weitere mögliche Maßnahmen bestehen in der Bindung an dienstliche Hard- und Software (z. B. über Gerätezertifikate oder die Bindung an Apps) oder gesicherte Netzzugänge (z. B. VPN), sodass das E-Mail-System nicht direkt aus dem Internet zugänglich ist, sondern nur über eine gesicherte Netzverbindung. Eine Verbindung „von jedem PC der Welt im Internetcafé“ ist dann nicht mehr möglich – und genau das ist das Ziel der Sicherheitsmaßnahmen.
Was ist zu tun?
Bei Datenpannen ist die Ursache sorgfältig zu ermitteln, damit sie abgestellt wird oder zumindest die Wahrscheinlichkeit von Wiederholungsfällen gesenkt wird.
6.3.2 Frag’ für ’nen Freund
Die Integration von künstlicher Intelligenz (KI) in Unternehmen und Behörden nimmt immer weiter zu und stellt sowohl die Organisationen als auch die Aufsichtsbehörden vor Herausforderungen. Häufig bestehen jedoch Hürden auf beiden Seiten: Organisationen befürchten aufsichtsbehördliche Maßnahmen, wenn sie Fragen stellen, und dass ihren KI-Projekten Steine in den Weg gelegt werden. Die Aufsichtsbehörden ihrerseits sind darauf angewiesen, die Probleme und Fragen der Organisationen zu kennen, die bei der Planung, Entwicklung und beim Einsatz von KI auftreten. Nur so können sie praxistaugliche Hinweise für die Konzeption, die Implementierung und den Betrieb von KI-Projekten anbieten. Ziel dabei ist, dass Datenschutzanforderungen bereits in der Entwicklungsphase von KI-Anwendungen berücksichtigt werden, statt sie nachträglich mit hohem Aufwand einbauen zu müssen.
Hier setzt das Konzept „Frag’ für ’nen Freund“ an, das einen offenen Rahmen für den Austausch von Wissen und Erfahrungen zwischen Organisationen und Aufsichtsbehörden bietet. Dieses Format schafft eine vertrauensvolle Gesprächsatmosphäre, in der Teilnehmende Fragen stellen können, ohne negative Konsequenzen befürchten zu müssen. Zusätzlich fördert diese Form der Veranstaltung das Verständnis zwischen beiden Seiten, kann Missverständnisse ausräumen und bietet einen Rahmen für einen direkten, fachlichen Austausch.
Im November fand in den Räumen des ULD die erste „Frag’ für ’nen Freund“-Veranstaltung zum Thema KI statt. Die Teilnehmenden aus Unternehmen, Behörden und Kanzleien diskutierten zu KI-Fragestellungen und brachten ihre Erfahrungen und Fragestellungen ein. In einer abschließenden Feedbackrunde waren sich alle Teilnehmenden einig, dass dieses Format auch zukünftig genutzt werden soll, um den Austausch von KI-Expertise zu fördern. Unternehmen, Behörden und Aufsichtsbehörde haben so die Möglichkeit, auf Augenhöhe miteinander zu kommunizieren – ein wichtiger Schritt, um das Verständnis für die praktischen Anwendungen von KI und die damit verbundenen regulatorischen Anforderungen zu stärken.
Unter diesem Link gibt es weitere Informationen:
https://www.datenschutzzentrum.de/artikel/1495-Frag-fuern-Freund-Austausch-rund-um-KI-und-Datenschutz.html
Kurzlink: https://uldsh.de/tb43-6-3-2a
Was ist zu tun?
Auf der Website des ULD können sich interessierte Personen auf einer Mailingliste eintragen, um Informationen zu KI & Datenschutz zu erhalten und über zukünftige „Frag‘ für ’nen Freund“-Veranstaltungen informiert zu werden.
6.3.3 Fragen in der Telefonberatung: Passwörter, E-Mail-Provider und PayPal-Phishing
In der telefonischen Beratung begegnen wir regelmäßig technischen Herausforderungen, von denen im Berichtsjahr zwei besonders herausragten: der Verlust von Onlinezugängen und betrügerische PayPal-Anrufe.
Der Verlust von Onlinezugängen, sei es durch Fremdübernahme oder selbst verschuldete Aussperrung, ist ein Dauerbrenner in der telefonischen Beratung. Besonders kritisch ist dabei der Verlust des E-Mail-Kontos, da dieses oft als zentrale Schaltstelle für viele andere Onlinedienste dient. Haben Unbefugte Zugriff auf das E-Mail-Konto, können sie über die üblichen Passwort-Zurücksetzungsfunktionen schnell weitere Konten des Opfers übernehmen. Die Situation verschärft sich, wenn der E-Mail-Anbieter keinen technischen Support bietet. Dies trifft besonders auf Anbieter kostenloser E-Mail-Dienste (Freemailer) zu, die ihren Support üblicherweise zahlenden Kunden vorbehalten und Gratisnutzer lediglich auf Chatbots oder kostenpflichtige Hotlines verweisen. Wir empfehlen daher, sich bereits bei der Wahl des E-Mail-Anbieters über dessen Supportangebot im Notfall zu informieren und die möglichen Hilfswege vorab zu kennen.
Die beste Absicherung gegen unerwünschte Kontozugriffe bietet nach wie vor die Zwei-Faktor-Authentifizierung. Ist diese aktiviert, reicht ein erbeutetes Passwort allein nicht aus – Angreifer benötigen zusätzlich den Code vom Smartphone oder einen registrierten USB-Stick. Diese zweite Sicherheitsebene schützt Onlinekonten selbst dann noch, wenn das eigene E-Mail-Konto bereits kompromittiert wurde.
Ein weiteres aktuelles Phänomen sind betrügerische Anrufe von angeblichen PayPal-Beschäftigten. Diese melden sich auf Englisch und behaupten, vom Konto der Angerufenen sei ein größerer Betrag für den Kauf von Bitcoins abgebucht worden. Der Betrug folgt dabei einem wiederkehrenden Gesprächsmuster: Man bietet an, die angebliche Zahlung rückgängig zu machen, besteht aber darauf, zunächst die Kontosicherheit wiederherzustellen. Man führt die Opfer telefonisch auf eine Website, die deren IP‑Adresse mit einer Warnung versehen anzeigt, und behauptet fälschlicherweise, die IP-Adresse sei „gehackt“ worden (eine Aussage, die technisch natürlich wenig Sinn ergibt). Als vermeintliche Lösung fordert man die Installation einer Fernwartungs-App über den App-Store. Glücklicherweise wurden die Personen, die sich an das ULD wandten, an dieser Stelle misstrauisch und beendeten das Gespräch, bevor die Betrüger Zugriff auf ihre Smartphones erlangen konnten.
Die PayPal-Anrufe folgen dem klassischen Betrugsmuster, zunächst eine Stresssituation zu erzeugen, um die Betroffenen zu schnellen und unüberlegten Reaktionen zu provozieren. Dabei war es in diesem Fall recht leicht, den Betrug zu entlarven: Die angerufene Person fragte einfach nach, um welche PayPal-Adresse es denn eigentlich ginge – prompt legte die Gegenseite auf. Nachfragen und Präzisierungen sind dementsprechend ein gutes Mittel, um in vermeintlichen Stresssituationen sowohl ein wenig Zeit zum Nachdenken als auch Klarheit über die Intention der Anrufenden zu erhalten.
Was ist zu tun?
(Vermeintlich) wohlmeinenden Anrufen, die Sicherheitsvorfälle melden, sollte man kritisch begegnen. Rückfragen schaffen Zeit zum Nachdenken und entlarven manchen Betrug.
6.3.4 Modulare Dokumentation – Rechenschaftspflicht mit System
Organisationen müssen sicherstellen, dass sie die Anforderungen der Datenschutz-Grundverordnung (DSGVO) und – soweit einschlägig – des Landesdatenschutzgesetzes in ihren Verfahrensweisen integrieren. Die Rechenschaftspflicht nach Art. 5 Abs. 2 DSGVO und Artikel 24 DSGVO verlangt, dass nicht nur die gesetzlichen Anforderungen zu erfüllen sind, sondern dies auch jederzeit nachgewiesen werden kann. Hieraus ergibt sich eine Pflicht zur Dokumentation.
Verantwortliche müssen sicherstellen, dass alle Grundsätze der DSGVO – von der Rechtmäßigkeit über die Zweckbindung bis hin zu Integrität und Vertraulichkeit – in jeder Phase der Datenverarbeitung beachtet werden. Darüber hinaus gilt es, die Umsetzung spezifischer Anforderungen zu belegen: von der Sicherstellung von Betroffenenrechten über die Implementierung geeigneter technischer Maßnahmen bis hin zur Einbindung von Datenschutzbeauftragten. Für öffentliche Stellen in Schleswig-Holstein kommen zusätzliche Anforderungen hinzu, z. B. das vom Landesdatenschutzgesetz (LDSG SH) geforderte Test- und Freigabeverfahren für automatisierte Verarbeitungen. Die Komplexität dieser Anforderungen verdeutlicht die Notwendigkeit eines gut geplanten und strukturierten Ansatzes zur Datenschutzdokumentation.
Die Herausforderung besteht darin, die Dokumentationspflichten nicht als lästige Pflicht, sondern als Chance zu begreifen. Eine gut strukturierte Dokumentation bietet die Möglichkeit, Transparenz zu schaffen, Vertrauen aufzubauen und die eigenen Datenschutzprozesse kontinuierlich zu optimieren. Sie bildet das Fundament eines effektiven Datenschutzmanagements und ermöglicht es Organisationen, jederzeit nachzuweisen, dass sie die Datenschutzvorschriften einhalten und die Prüfbarkeit gewährleistet ist.
Wir haben einen Strukturierungsvorschlag entwickelt, um das Datenschutzmanagement zu organisieren. Ziel dieses Vorschlags ist es, einen grundlegenden Rahmen zu schaffen, der es Organisationen ermöglicht, ihre Dokumentation systematisch und übersichtlich zu gestalten. Die konkreten Inhalte der einzelnen Dokumentationsbausteine müssen jedoch individuell von jeder Organisation erarbeitet werden, da sie stark von den spezifischen Verarbeitungstätigkeiten, der eingesetzten Technik, den organisatorischen Strukturen und den besonderen Risiken der jeweiligen Datenverarbeitung abhängen.
Der vorliegende Strukturierungsvorschlag unterteilt sich in drei Hauptbereiche, die jeweils einen spezifischen Aspekt der Dokumentation abdecken: Kerndokumentation, IT-Dokumentation und Dokumentation der Verarbeitungstätigkeiten. Die gesamte Dokumentation ist hierarchisch auf zwei Ebenen aufgebaut und nutzt einen modularen Ansatz mit „Was-Bausteinen“ und „Wie-Bausteinen“. Zudem hilft diese Struktur, Redundanzen zu vermeiden, da jede Information nur in einem Baustein dokumentiert wird. Alle anderen Bausteine können dann auf diesen verweisen. Auf diese Weise können Änderungen, Anpassungen oder Fehler in den einzelnen Bausteinen leicht vorgenommen werden, ohne dass die gesamte Dokumentation überarbeitet werden muss.
Die Verarbeitungsdokumentation ist das zentrale Element des Datenschutzmanagements in Organisationen. Aus diesem Grund stellt das ULD sowohl für die Erfüllung der Rechenschaftspflicht als auch zur Erfüllung der Informationspflichten zusätzliche Dokumentationsvorlagen und Erläuterungen zur Verfügung. Sie können als roter Faden für die Dokumentation angesehen werden.
Der Strukturierungsvorschlag und die Dokumentationsvorlagen mit ihren Erläuterungen können auf der Website des ULD unter dem folgenden Link heruntergeladen werden:
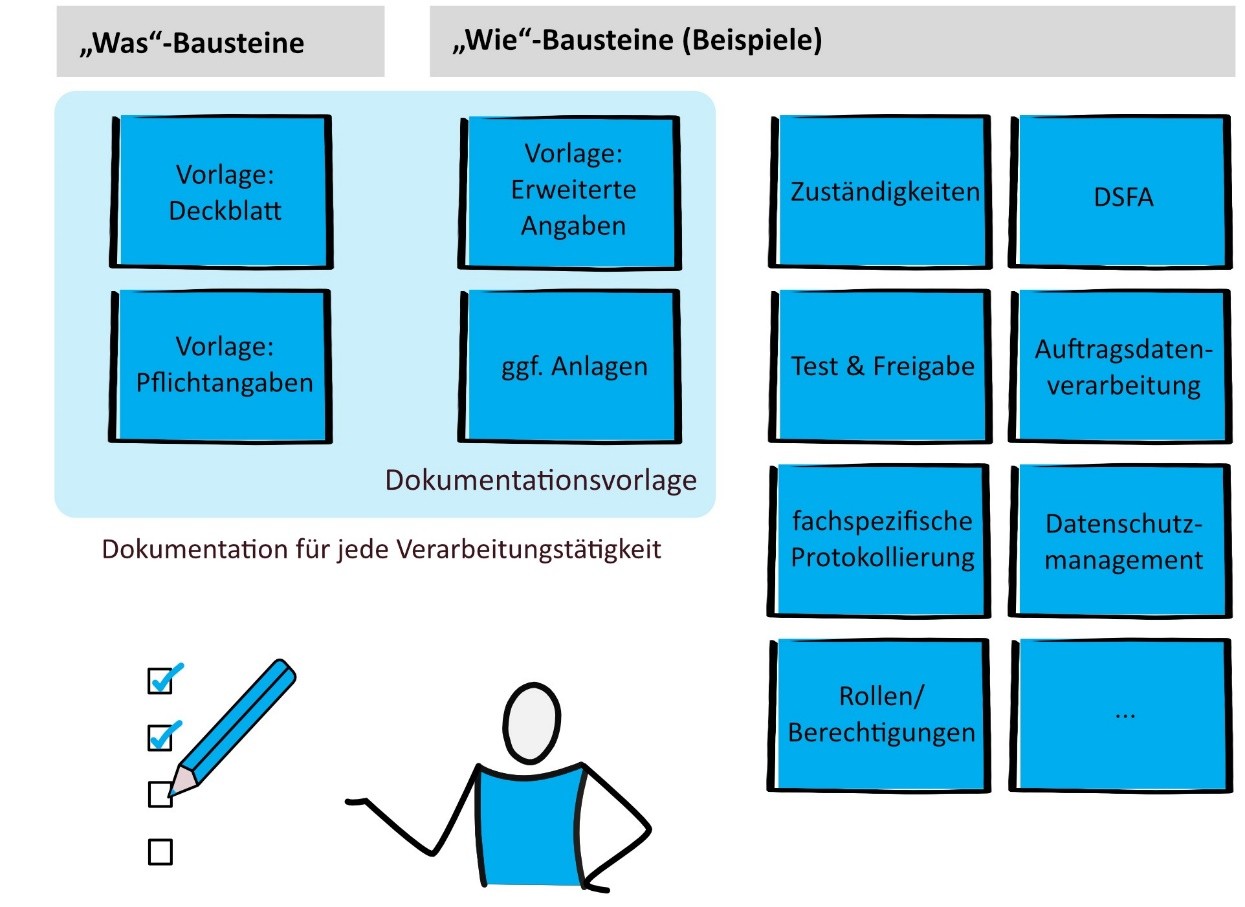
Abb 4: Verarbeitungsdokumentation
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


