Kernpunkte:
- Plattform Privatheit
- Transparenz- und Einwilligungsmanagement
- AnoMed – Kompetenzcluster Anonymisierung für medizinische Anwendungen
8 Modellprojekte und Studien
Das Unabhängige Landeszentrum für Datenschutz hat als Behörde der Landesbeauftragten für Datenschutz seine Aktivitäten in Initiativen im Bereich drittmittelfinanzierter Projekte und Studien fortgesetzt. Damit ist das ULD weiterhin im Bereich der Kooperation mit der Wissenschaft aktiv und erhält sich damit die Möglichkeit, zusammen mit Wissenschaftspartnern proaktiv an der Erforschung datenschutzspezifischer Fragen und der Gestaltung einschlägiger Technologien mitzuwirken.
Im Berichtszeitraum wurden Projekte von der Europäischen Kommission und dem Bundesministerium für Bildung und Forschung (BMBF) gefördert. Beteiligungen an Projekten erfolgten weiterhin primär dort, wo entweder besondere datenschutzfördernde Lösungen (englisch: „Privacy-Enhancing Technologies“, kurz PETs) erforscht und entwickelt werden oder wo besondere Risiken für die Rechte und Freiheiten natürlicher Personen bestehen.
Im Jahr 2023 beteiligte sich das ULD an Projekten zu aktuellen Themen in den Bereichen Privatheit und selbstbestimmtes Leben (Tz. 8.1), Überführung von Lösungen des Datenschutzes durch Technikgestaltung in die Praxis (Tz. 8.2) sowie Transparenzprobleme des Internets der Dinge (Tz. 8.3). Zudem setzte das ULD sein Engagement für Datenschutz, Transparenz und Einwilligungsmanagement fort (Tz. 8.4) und befasste sich mit der Anonymität für Medizinforschung mit Gesundheitsdaten (Tz. 8.5).
8.1 Plattform Privatheit: PRIDS – Privatheit, Demokratie und Selbstbestimmung
Der bereits im letztjährigen Tätigkeitsbericht (41. TB, Tz. 8.1) angekündigte Wechsel vom Forum Privatheit zur Plattform Privatheit wurde nun sehr sichtbar auf der letztjährigen Jahreskonferenz der Plattform Privatheit vollzogen. Die Jahreskonferenz ist eine von mehreren Veranstaltungen der Plattform zur Präsentation von Arbeitsergebnissen und dem wissenschaftlichen Austausch mit anderen Forschenden. Die Konferenz hatte das Thema „Data Sharing – Datenkapitalismus by Default?“ gewählt und befasste sich u. a. mit den neuen Datenräumen zur Gesundheit und Mobilität. Die Konferenz hinterfragte dabei auch die weiter voranschreitende Kommerzialisierung dieser Lebensbereiche, die zu einer Einengung der Handlungsspielräume der Bürgerinnen und Bürger zugunsten großer Technikunternehmen (Big Tech) führt.
Datengerechtigkeit
Das Forschungsfeld der Datengerechtigkeit (Data Justice) untersucht, wie sich Datenpraktiken von Unternehmen, aber auch staatlicher Seite, auf Bürgerinnen und Bürger auswirken. Die negativen Auswirkungen treffen meist Personengruppen, die bereits in anderen Lebensbereichen benachteiligt werden, z. B. Frauen, schwarze Menschen oder Lesben, Schwule, Bisexuelle und Trans*personen. Ihre Bedürfnisse werden bei der Gestaltung von Datenverarbeitung nicht immer ausreichend berücksichtigt.
Im Jahr 2023 befassten wir uns auch mit Fragen von Gerechtigkeit bei der Verarbeitung von Daten für alle Bürgerinnen und Bürger, der Datengerechtigkeit. Dabei ging es darum, Probleme zu identifizieren und Lösungsansätze zu entwickeln. Ein Problem ist etwa die fehlende Einbindung bestimmter Personengruppen bei der Gestaltung von Datenverarbeitung. Dies führt dazu, dass viele Software-Anwendungen eigentlich nur für eine oder wenige bestimmte Personengruppen zuverlässig funktionieren.
Ein Beispiel sind Bildgeneratoren, die als Anwendungen der sogenannten künstlichen Intelligenz inzwischen in vielen Varianten verfügbar sind. Allerdings produzieren sie oft nur stereotypische Darstellungen von schwarzen Menschen oder stellen Frauen und Mädchen in übersexualisierter Weise dar. Ein Lösungsansatz besteht darin, die (Trainings-)Daten, auf denen diese Anwendungen basieren, besser zu überwachen, damit keine einseitigen, verfälschenden oder gar toxischen Inhalte eingeführt werden.
https://www.plattform-privatheit.de/
Kurzlink: https://uldsh.de/tb42-8-1a
8.2 Projekt DatenTRAFO – Neue Datenschutz-Governance – Technik, Regulierung und Transformation
Das vom BMBF geförderte Projekt „DatenTRAFO – Neue Datenschutz-Governance – Technik, Regulierung und Transformation“ ist im September 2023 gestartet. Es beschäftigt sich mit der Frage, wie der Systemdatenschutz, der bereits insbesondere in Artikel 25 und Artikel 32 DSGVO verlangt wird, ausgebaut werden kann.
Systemdatenschutz bietet Möglichkeiten, Datenschutz von Beginn an und während des gesamten Verarbeitungsvorgangs zu gewährleisten und auf diese Weise Bürgerinnen und Bürger sowie den demokratischen Rechtsstaat zu schützen. Dafür untersucht das Projekt, wie sich vorhandene Verfahren und Produkte des technischen Datenschutzes vermehrt in der Praxis einsetzen lassen.
Zu den Tätigkeiten im Projekt gehört auch eine Analyse, wie Regulierung, Standards und Zertifizierungen gestaltet werden können, um datenschutzfreundliche Lösungen zu befördern und die Grundrechte von Bürgerinnen und Bürgern besser durchsetzen zu können. Dabei werden auch Fragen der digitalen Souveränität mit einem Fokus auf den Umgang mit oder das Reduzieren von Abhängigkeiten, beispielsweise von mächtigen Digitalkonzernen, eine Rolle spielen.
https://www.datenschutzzentrum.de/projekte/datentrafo/
Kurzlink: https://uldsh.de/tb42-8-2a
8.3 Projekt Unboxing.IoT.Privacy – Transparenz für Datenschutzeigenschaften von IoT-Geräten
Das ULD ist seit November 2023 an dem vom BMBF geförderten Verbundprojekt „Tool-gestützte, moderierte und bürgerzentrierte Community-Plattform zur Privacy-Einstufung von IoT-Produkten – Unboxing.IoT.Privacy“ beteiligt.
Das Internet der Dinge (englisch: „Internet of Things“, IoT) weist ein hohes Potenzial auf und bringt die Vorteile von Digitalisierung und Vernetzung direkt zu den Menschen. Damit birgt es zugleich Gefahren für die Rechte und Freiheiten der betroffenen Personen. Für das ULD ist daher nicht nur wichtig, dass die damit zusammenhängenden Verarbeitungen personenbezogener Daten auf Basis einer geeigneten Rechtsgrundlage erfolgen, sondern auch dass Betroffene über eine Datenverarbeitung angemessen informiert werden und eingreifend reagieren können.
Das ULD beteiligt sich an dem Projekt Unboxing.IoT.Privacy mit dem Ziel, das Internet of Things verständlicher zu machen. Bürgerinnen und Bürgern soll es ermöglicht werden zu wissen und soweit möglich zu beeinflussen, wer welche Informationen zu welchen Zwecken wo und wie über sie erhebt, verarbeitet, speichert und nutzt – ganz im Sinne des Rechts auf informationelle Selbstbestimmung.
Internet of Things
Das Internet der Dinge (englisch: „Internet of Things“, IoT) beschreibt Technologien, die physische und virtuelle Objekte mithilfe von Informations- und Kommunikationstechnik zusammenwirken lassen. So können mittels Sensoren Informationen aus der realen Welt erfasst werden, die sich dann weiterverarbeiten lassen, z. B. übermittelt, verknüpft oder im Netz bereitgestellt werden. Umgekehrt können Aktoren die physische Welt beeinflussen, Türen öffnen, Lichter schalten oder den heimischen Saugroboter steuern.
Zwingende Vorbedingung hierfür ist indes, dass diejenigen, die IoT-Geräte einsetzen, ihrerseits hinreichend über die Verarbeitung personenbezogener Daten, das damit verbundene Risiko und Maßnahmen zur Risikobeherrschung informiert sind. Das ist die Grundlage dafür, Auswahl- und Kaufentscheidung sowie Konfiguration der Geräte angemessen durchführen zu können und als Verantwortliche Informationen über den Einsatz verständlich an Betroffene zu vermitteln.
Mit der Frage, wie eine übersichtliche Kurzdarstellung datenschutzrelevanter Kerninformationen gelingen könnte, haben sich die Teams der Uni Göttingen und des ULD bereits im europäisch geförderten Projekt „Privacy&Us“ befasst (37. TB, Tz. 8.6.3). Dabei wurde immer wieder offensichtlich, dass es schlicht an den Informationen über die IoT-Geräte, deren Eigenschaften, Einstellungsoptionen, die vorgesehenen Übermittlungen an Hersteller und Dienstleister und weitere Akteure fehlt. Die Projektziele von Unboxing.IoT.Privacy sind klare Beiträge zur Informationsbeschaffung sowie zur anschließenden Einschätzung, Gewichtung und Aufbereitung unter dem Gesichtspunkt des Datenschutzes. Technikpartner aus Wissenschaft und Wirtschaft erforschen Analysemöglichkeiten, etwa zur automatisierten Auswertung und Analyse der Geräte selbst, verfügbarer Software und vorhandener Datenschutzerklärungen.
Aufgabe des ULD-Teams im Projekt ist, eine zielgruppengerechte Berücksichtigung der Datenschutzperspektive bei Bewertung, Gewichtung und Darstellung der erlangten Informationen zu erarbeiten. Ob Verbraucherinnen und Verbraucher, Unternehmen oder Behörde, eine Kaufentscheidung für vernetzte Geräte sollte sorgfältig und informiert erfolgen können.
Verbraucherinnen und Verbraucher profitieren dabei unmittelbar von verständlicher Transparenz. Beim Einsatz von IoT-Geräten fallen oft personenbezogene Daten auch von Dritten an, etwa weiteren Haushaltsangehörigen, Gästen, Passanten oder Straßenverkehrsteilnehmern. Diejenigen, die solche vernetzten Geräte jenseits des eng gesteckten Rahmens persönlicher oder familiärer Tätigkeiten einsetzen, treffen die datenschutzrechtlichen Pflichten von Verantwortlichen: insbesondere das Vorhandensein einer Rechtsgrundlage, die Bereitstellung von Information an betroffene Personen, Gewährleistung technischer Sicherheit und fristgemäße Löschung von Daten. Darüber hinaus profitieren natürlich auch Behörden oder Wirtschaftsunternehmen als Verantwortliche von klaren Informationen für ihre Kaufentscheidungen, etwaige Datenschutz-Folgenabschätzungen und generelle Dokumentations- und Compliance-Pflichten.
https://www.datenschutzzentrum.de/projekte/unboxingiot/
Kurzlink: https://uldsh.de/tb42-8-3a
Was ist zu tun?
Mit dem Internet verbundene Produkte sind besonders sorgfältig auszuwählen, um das angemessene Schutzniveau für die betroffenen Personen gewährleisten zu können. Der Verantwortliche muss seinen Informationspflichten gegen über den betroffenen Personen nachkommen.
8.4 Projekt TRAPEZE – Transparenz- und Einwilligungsmanagement für das semantische Netz
Das Projekt „TRAnsparency, Privacy and security for European citiZEns“ (TRAPEZE) wurde von der EU-Kommission gefördert und widmete sich der Entwicklung von Lösungen für Datenschutz und Transparenz in der „Data Economy“ (41. TB, Tz. 8.4). Im Sommer 2023 lief das Projekt aus. Die letzten Projektmonate waren u. a. der öffentlichen Vorstellung und Erörterung der Projektergebnisse gewidmet.
Zu den Zielen von TRAPEZE gehörten verbesserte Transparenz und einfachere Mitwirkungsmöglichkeiten für betroffene Personen. Zentrale Zielgruppen zur Vorstellung und Erörterung der Ergebnisse waren damit Datenschutzaufsichtsbehörden, aber auch Behörden mit Fokus auf IT-Sicherheit und die Anwender aus dem betrieblichen und behördlichen Datenschutz. Unter dem Dach einer Konferenz mehrerer europäischer Forschungsprojekte zu Datenschutz und Cybersicherheit in Sophia Antipolis, Frankreich, richtete das ULD im April 2023 einen Workshop aus. Der Teilnehmerkreis vor Ort und online umfasste Vertreter diverser Datenschutzaufsichtsbehörden aus Europa und der Welt. Die ausgewählten Kernpunkte der Agenda waren:
- Sticky Policies, d. h. computerlesbare Datenschutzerklärungen, die zusammen mit den betroffenen Daten weitergegeben werden können und im Projekt weiterentwickelt wurden,
- ein Privacy Dashboard, das die genannten Policies übersichtlich darstellen kann und Nutzenden eine überschaubare und einfache Oberfläche zum Erteilen, Widerrufen und Management von Einwilligungen bietet,
- ein Brückenschlag zwischen aktuellen legislativen Entwicklungen und dadurch aufgeworfenen Herausforderungen zu möglichen Lösungen aus der Forschung und Entwicklung zu Datenschutz durch Technikgestaltung.
Die grundsätzliche Idee der Sticky Policies ist nicht neu und wurde schon in den 2000ern erörtert (30. TB, Tz. 8.2). Die weiterentwickelte Sprache zur computerlesbaren Wiedergabe von Berechtigungen und Einschränkungen für die Datenverarbeitung spiegelt die Rechtsgrundlagen und Verarbeitungsbedingungen aus der DSGVO wider. Sie wird von einer Arbeitsgruppe unter dem Dach des W3C kontinuierlich erweitert und weiterentwickelt. Das Projekt TRAPEZE trug zum Konzept der Policies neben konzeptionellen Verbesserungen vor allem mit technischen Entwicklungen zum praktischen Einsatz im Unternehmensumfeld bei.
Das Privacy Dashboard wurde gegenüber der Fassung aus dem Vorjahr (41. TB, Tz. 8.4) finalisiert. Im Vergleich zu langen textbasierten Einwilligungstexten oder Datenschutzerklärungen hebt sich eine Darstellung über das Dashboard durch Übersichtlichkeit ab. Einträge lassen sich etwa nach Zwecken, Datenarten oder möglichen Empfängern bzw. Empfängerkategorien sortieren. Betroffenenrechte werden insbesondere im Bereich der Transparenz unterstützt, und das nutzerseitige Management von Einwilligungen und deren Reichweite bedient Aspekte der Intervenierbarkeit. Daneben ist eine direkte Kontaktaufnahme zum Verantwortlichen bzw. der dortigen Datenschutzabteilung vorgesehen.
Die den Workshop abschließende Erörterung der Bezüge zu aktuellen Entwicklungen nahm u. a. die Forschung mit Gesundheitsdaten in den Blick. Mit dem Europäischen Raum für Gesundheitsdaten (European Health Data Space, EHDS) ergeben sich auf der einen Seite erhebliche Potenziale für die Medizinforschung. Auf der anderen Seite fehlen für die gewünschte breite Zweitnutzung von Gesundheitsdaten zu Forschungszwecken angemessene Transparenzlösungen. Sticky Policies oder Dashboards könnten hier bei der technischen und organisatorischen Gestaltung des Datenraums wichtige Beiträge leisten. Auch im Vergleich zu den derzeit üblichen sehr weiten Einwilligungsregelungen (broad consent) wären übersichtlichere und für die Betroffenen granular regelbare Einwilligungen ein Vorteil.
Für Sticky Policies sahen die an der Diskussion Teilnehmenden auch jenseits des Managements personenbezogener Daten Anwendungsfelder. So könne das Konzept prinzipiell auch zur Beschreibung von Berechtigungen und Beschränkungen nicht nur für den Datenschutz, sondern auch für Geschäftsgeheimnisse oder gewerbliche Schutzrechte dienen und könnten damit als Maßnahmen für „Informationsfreiheit by Design“ (Tz. 12.5) zum Einsatz kommen. Denkbare Anwendungsfelder fänden sich dafür auch im Rahmen der weiteren geplanten europäischen Datenräume.
Das TRAPEZE-Projekt konnte einige datenschutzfördernde Konzepte weiterentwickeln und prototypisch zeigen, wie sie im Unternehmensumfeld verwendbar wären. Es ist zu wünschen, dass einige dieser und verwandter Innovationen Eingang in Produkte oder Verfahren in der Wirtschaft fänden. Weiterführende Forschungsfragen für die Zukunft betreffen eine Gestaltung und Bereitstellung datenschutzfördernder Technik in einer Art und Weise, dass heute manches Mal noch bestehende Einstiegshürden vermieden oder zumindest gesenkt werden. Wünschenswert wäre insoweit, dass sowohl Internetnutzende als auch kleinere Unternehmen diese verwenden können. Konkretes Potenzial mit Mehrwert für Betroffene als auch Verantwortliche bestünde etwa für eine einfache Umsetzung von Widerrufen einer Einwilligung und Widersprüchen.
https://www.datenschutzzentrum.de/projekte/trapeze/
Kurzlink: https://uldsh.de/tb42-8-4a
8.5 Projekt AnoMed – Kompetenzcluster Anonymisierung für medizinische Anwendungen
Der im November 2022 gestartete und vom Bundesministerium für Bildung und Forschung sowie der Europäischen Union (NextGenerationEU) geförderte Kompetenzcluster „Anonymisierung für medizinische Anwendungen“ (AnoMed) (41. TB, Tz. 8.5) bündelt Anonymisierungsforschung für den Gesundheitsbereich. Die Gesundheitsforschung ist politisch bedeutend: Mit dem Europäischen Raum für Gesundheitsdaten (European Health Data Space, EHDS) soll die Blaupause für weitere Datenräume geschaffen werden. Es ist vorgesehen, vorhandene Daten nach Themenbereichen zusammenzuführen und für Zwecke wie Forschung, Entwicklung oder Verwaltung zu nutzen. Es wird daher notwendig, dass alle Beteiligten sich klar über Schutzmaßnahmen für betroffene Personen austauschen. Dazu gehören auch Anonymisierung und Pseudonymisierung der Daten.
Ein Ergebnis der Tätigkeiten im Projekt ist der Vorschlag einer Terminologie über Personenbezug und Anonymisierung. Ziel ist ein Brückenschlag für Anonymisierungsforschung und Entscheidungsträgern in Politik, Forschung und Verwaltung. Notwendig wird eine kritische Aufbereitung der verwendeten Begrifflichkeiten insbesondere aufgrund der Risiken, die sich aus aktuellen und absehbaren Entwicklungen ergeben:
- Die Verfügbarkeit zusätzlicher Informationen muss stärker in den Fokus genommen werden. Eine Verknüpfung mit anderen verfügbaren Daten kann ermöglichen, dass Rückschlüsse auf Einzelpersonen in als „sicher“ gewähnten Datensätzen ermöglicht werden. Die leichte Verfügbarkeit großer und detaillierter Datenbestände resultiert u. a. aus neuen Techniken zur lückenlosen Datenerhebung, etwa Fitnesstrackern und Smartwatches.
- Der politische Wille zielt darauf ab, vorhandene Datenbestände künftig europaweit systematisch in anonymisierter Form für Zwecke der Forschung und Innovation z. B. im öffentlichen Gesundheitswesen und in der Verwaltung im Rahmen von sogenannten Datenräumen zur Verfügung zu stellen und großflächig auszuwerten.
- Künstliche Intelligenz und andere Entwicklungen machen die Analyse großer Datenmengen einschließlich Verkettung von Informationen einfacher. Das Risiko besteht nicht nur bei der Verwendung von Identifikatoren wie dem Namen oder einer Personennummer, sondern Verkettbarkeit und Profilbildung können auch auf Basis von Kombinationen verschiedener Einzelwerte erfolgen.
- Die Anonymitätsforschung entdeckt vermehrt neue Angriffe auf als anonym geglaubte Daten, entwickelt aber ebenso Ansätze, die mathematisch belegbare Garantien gegen eine Re-Identifizierung aufweisen.
Die im AnoMed-Projekt vorgenommene Betrachtung greift die grundlegenden Darstellungen zur Identifizierbarkeit aus dem PANELFIT-Projekt auf (40. TB, Tz. 8.3). Die vorgeschlagene Terminologie beschränkt sich dabei bewusst auf die faktischen und technischen Aspekte von Maßnahmen zur Verringerung des Personenbezugs und die Beschreibung des Restrisikos für betroffene Personen. Zugleich wird eine klarere und differenzierte Begrifflichkeit vorgeschlagen. Damit wird ein Austausch über Einzelfälle und über Maßnahmen, die für bestimmte Szenarien funktionieren können, erleichtert. Die rechtliche Entscheidung, ob ein Personenbezug verbleibt, bleibt indes bewusst der Anwendungspraxis der Aufsichtsbehörden überlassen. Für die nächste Zeit sind die überarbeiteten Leitlinien zur Anonymisierung des Europäischen Datenschutzausschusses und Ausführungen des Europäischen Gerichtshofs in der Rechtsmittelsache EDPS v SRB zu erwarten.
Die vorgeschlagene Terminologie kategorisiert diverse Techniken zur Pseudonymisierung oder Anonymisierung von Daten oder – allgemeiner ausgedrückt – zur „Reduktion der Identifizierbarkeit“. Dabei können drei grundlegende Typen unterschieden werden:
- Pseudonymisierung,
- eine Reduktion der Identifizierbarkeit auf Ebene von Einzeldatensätzen oder
- Aggregation.
Die Grafik veranschaulicht, wie weitreichend die Methoden die Identifizierbarkeit erschweren und auf welche Datenkategorien die jeweiligen Techniken einwirken.
Bei einer Pseudonymisierung werden direkt identifizierende Informationen wie Namen oder Patientennummern entfernt und gegebenenfalls mit einem Pseudonym ergänzt, sodass eine Zusammenführung mit den abgesonderten Identitätsdaten möglich bleibt. Sollen die Daten weiterhin jeweils zu einer Person gehören, können typische quasi-identifizierende Informationen entfernt werden. Diese können zwar nicht direkt, aber eben doch in ihrer Zusammenschau den Rückschluss auf eine Person ermöglichen. Ist zudem gewährleistet, dass jedes Individuum mindestens Teil einer Gruppe mit definierter Mindestgröße ist, kann die Re-Identifikation erheblich erschwert sein.
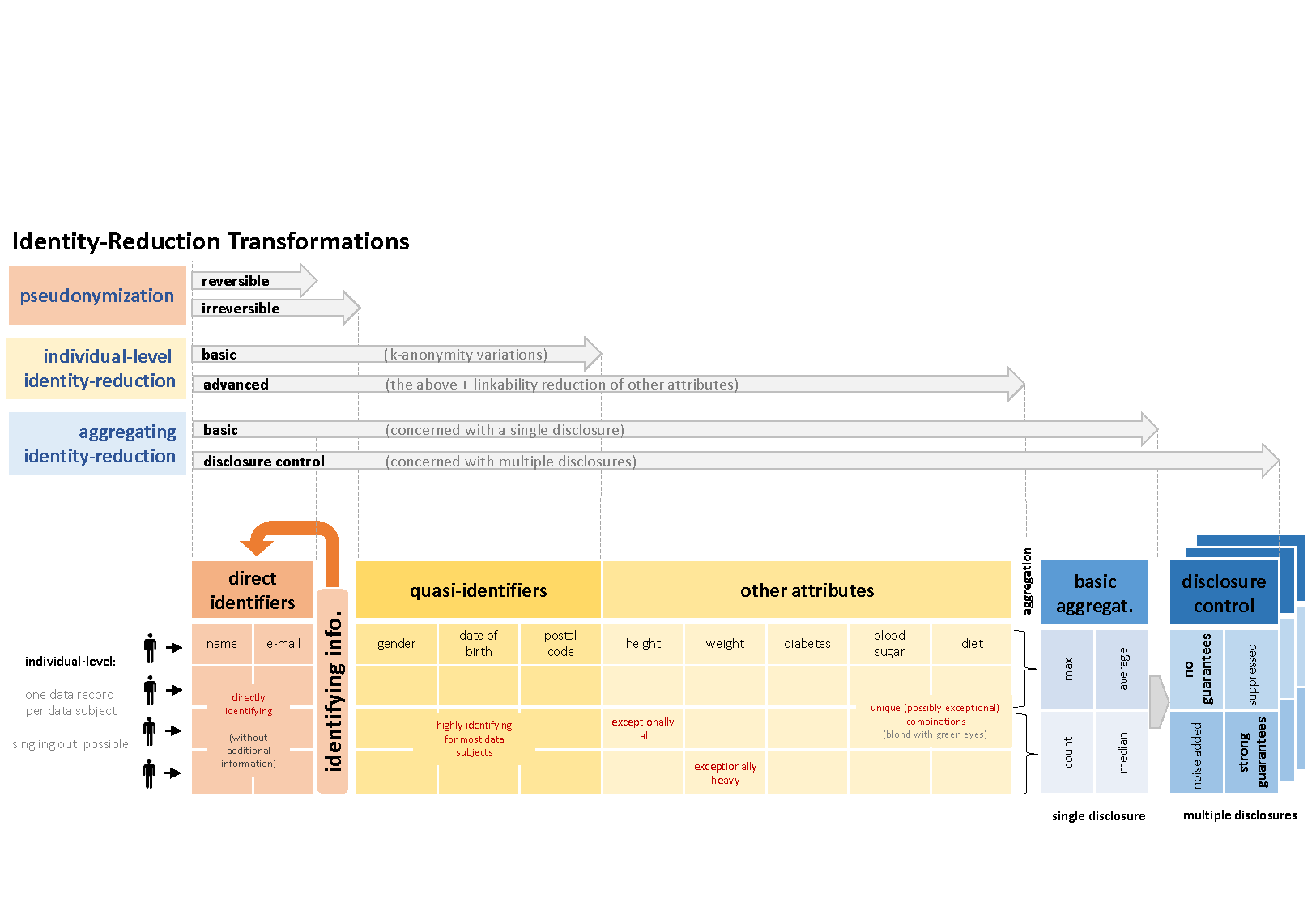
Abbildung: Techniken zur Verringerung der Identifizierbarkeit [Zum Vergrößern auf das Bild klicken]
Die Identifizierbarkeit wird schließlich weiter eingeschränkt, wenn die Daten nicht mehr pro Individuum vorgehalten werden. Nach einer Aggregation der Daten z. B. mittels statistischer Methoden ist als zusätzliche Hürde ein Aussortieren der zu einer Person gehörenden Informationen (singling out) erforderlich. Für Zwecke der Weitergabe oder Veröffentlichung könnten aggregierte Daten zudem mittels Rauschen verfremdet werden oder synthetische Daten erstellt werden.
Ergänzend ist eine kontinuierliche vorausschauende Beobachtung der Entwicklungen sinnvoll. Insbesondere verfügbare Informationen zur selben Personengruppe können trotz Aggregation Rückschlüsse ermöglichen. Die Daten können dabei aus derselben Datenquelle (z. B. im Rahmen von Ergebnisveröffentlichungen mehrerer Studien auf Grundlage von Daten aus dem EHDS) oder aus weiteren Quellen stammen.
Letztlich haben in der Praxis Verantwortliche zu entscheiden, ob Daten personenbezogen oder anonym sind. Sie sollten insbesondere vor der Veröffentlichung oder Weitergabe von sensiblen Informationen berücksichtigen, ob erhebliche Nachteile für betroffene Personen drohen.
Schwierigkeiten für alle Beteiligten bereitet eine Fehleinschätzung der Anonymität von Daten: Wenn diese dann unkontrolliert veröffentlicht werden und auch sonst – weil der Verantwortliche meint, dass die DSGVO für seine Verarbeitung der nur vermeintlich anonymen Daten nicht gilt – keine Schutzmaßnahmen bestehen, kann der Schaden für die betroffenen Personen groß sein. Dies kann aufsichtsbehördliche Verfahren und Schadensersatzforderungen gegen den Verantwortlichen nach sich ziehen.
Die Terminologie nebst Diagrammen ist in der jeweils aktuellen Fassung auf der Projektseite verfügbar. Arbeitssprache für den weiteren Austausch über Entwurfsfassungen ist Englisch, um der europäischen Dimension und dem interdisziplinären Bezug gerecht zu werden.
https://www.datenschutzzentrum.de/projekte/anomed/
Kurzlink: https://uldsh.de/tb42-8-5a
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


