Kernpunkte:
- Pseudonymisierung
- Künstliche Intelligenz
- DNS-over-HTTPS
10 Aus dem IT-Labor
10.1 Pseudonymisierungslösungen mit zahlreichen Facetten – nicht „One size fits all“
Ein in der DSGVO konkret genanntes Mittel für den Schutz der Grundrechte und Grundfreiheiten natürlicher Personen ist die Pseudonymisierung. Als einzige Maßnahme wird sie mit einer Begriffsbestimmung (Art. 4 Nr. 5 DSGVO) hervorgehoben. Pseudonymisierung kann als datenschutzfördernde Maßnahme dienen, indem die Identität eines Individuums in einem spezifischen Zusammenhang verborgen wird. Gerade bei der Verarbeitung einer großen Zahl oder besonders sensibler personenbezogener Daten ist die Pseudonymisierung oft eine empfehlenswerte ergänzende Maßnahme.
Pseudonymisierung
Pseudonymisierung
ist eine Verarbeitung von personenbezogenen Daten, bei der das Resultat ohne
Hinzuziehen von zusätzlichen Informationen nicht mehr einer spezifischen Person
zugeordnet werden kann. Nur diese zusätzlichen Informationen ermöglichen es,
die pseudonymisierten Daten einem Individuum zuzuordnen – beispielsweise in
Form einer Tabelle oder Berechnungsfunktion.
Beim Einsatz einer datenschutzkonformen Pseudonymisierung sind zahlreiche technische und organisatorische Anforderungen zu berücksichtigen, damit das Pseudonymisierungsverfahren zuverlässig und sicher eingesetzt werden kann, aus den pseudonymisierten Daten keine Rückschlüsse auf einzelne Personen gezogen werden können und auch weiterhin alle Betroffenenrechte der betroffenen Personen gewahrt bleiben.
Die Fokusgruppe Datenschutz der Plattform „Sicherheit, Schutz und Vertrauen für Gesellschaft und Wirtschaft“ hat im Rahmen des Digital-Gipfels der Bundesregierung 2018 eine umfangreiche Beschreibung all dieser Anforderungen an den datenschutzkonformen Einsatz von Pseudonymisierungslösungen vorgelegt. An dieser Arbeitsgruppe wirken Vertreterinnen und Vertreter von Unternehmen, aus Hochschulen, von Unternehmensverbänden sowie von zivilgesellschaftlichen Institutionen mit. Die Datenschutzaufsichtsbehörden sind über den Bundesbeauftragten für den Datenschutz und die Informationsfreiheit sowie über das ULD vertreten.
Als nächsten Schritt plant die Fokusgruppe die Finalisierung von Verhaltensregeln („Code of Conduct“) für Pseudonymisierung; ein Entwurf wurde schon beim Digital-Gipfel 2019 vorgelegt.
Die Verhaltensregeln sollen Verantwortlichen die Möglichkeit bieten, praxisorientiert passende organisatorische und technische Maßnahmen auszuwählen, Zuständigkeiten festzulegen und notwendige Prozesse einzuführen. Anhand von zwei Anwendungsbeispielen werden die Vorgaben und Fragestellungen näher erläutert. Der Entwurf soll in einem nächsten Schritt um sektorspezifische Good-Practice-Beispiele ergänzt werden. Vor der Genehmigung eines „Code of Conduct“ gemäß Art. 40 Abs. 2 Buchst. d DSGVO durch eine Aufsichtsbehörde müssen zudem Prozesse zur Kontrolle der Einhaltung des Codes festgelegt werden.
Der Entwurf für einen „Code of Conduct“ zum Einsatz DSGVO-konformer Pseudonymisierung ist unter folgendem Link abrufbar:
https://www.de.digital/DIGITAL/Redaktion/DE/Textsammlung/digital-gipfel-plattform-sicherheit-schutz-vertrauen-fg3.html [Extern]
Kurzlink: https://uldsh.de/tb38-101a
Auch auf europäischer Ebene wird der datenschutzfördernde Einsatz von Pseudonymisierung diskutiert. Mit einem gemeinsamen Workshop der Agentur der Europäischen Union für Cybersicherheit (ENISA) und des ULD am 12. November 2019 in Berlin konnte die aktuelle Debatte in verschiedenen Sektoren und Ländern gebündelt werden.
Im Rahmen des Workshops gelang ein interdisziplinärer Austausch zu erprobten Techniken für Pseudonymisierung und über verschiedene Erfahrungen. Eines der Hauptergebnisse des Workshops war, dass es nicht eine einzige Pseudonymisierungslösung gibt, die in allen Fällen angewendet werden kann. „One size fits all“ funktioniert hier nicht. Obwohl heute mehrere verschiedene technische Ansätze zur Verfügung stehen, sollte ein Risikobewertungsprozess – basierend auf dem Kontext und dem gewünschten Nutzungsgrad – für jeden einzelnen Fall das bestmögliche Verfahren vorsehen. Daher sind weitere Arbeiten an praktischen Beispielen und realen Umsetzungsszenarien sowohl auf der technischen als auch auf der rechtlichen Seite erforderlich.
Die Materialien des Workshops sowie der ENISA-Report „Pseudonymisation Techniques and Best Practices“ stehen online zur Verfügung:
https://www.enisa.europa.eu/events/uld-enisa-workshop/uld-enisa-workshop-pseudonymization-and-relevant-security-technologies [Extern]
Kurzlink: https://uldsh.de/tb38-101b
10.2 Ergebnisse der Datenschutz-Taskforce „Künstliche Intelligenz“
Künstliche Intelligenz (KI) hat in den letzten Jahren permanent an Bedeutung gewonnen. Dabei ist KI nicht nur eine technische Zukunftsvision, sondern KI-Systeme sind im Alltag angekommen, beispielsweise als unterstützende Systeme in der Forschung und Medizin, aber auch in Suchmaschinen, Sprachassistenten oder Online-Shops. Um eine rechtlich zulässige Verarbeitung von personenbezogenen Daten in KI‑Systemen sicherzustellen und Akzeptanz bei den Betroffenen zu erzeugen, müssen bei der Entwicklung und Anwendung von KI hohe Anforderungen an technisch-organisatorische Maßnahmen und Standards in Bezug auf Datenschutz und Datensicherheit gestellt werden.
Die Konferenz der unabhängigen Datenschutzaufsichtsbehörden des Bundes und der Länder (DSK) hat Anfang 2019 eine Taskforce „KI“ ins Leben gerufen, die in einem ersten Schritt die grundsätzlichen Anforderungen an KI-Systeme erarbeitet hat. Diese Grundsatzerklärung wurde am 3. April 2019 von der DSK als „Hambacher Erklärung zur Künstlichen Intelligenz“ verabschiedet. Kernpunkte der Hambacher Erklärung sind sieben Datenschutzanforderungen an KI‑Systeme:
(1) KI darf Menschen nicht zu Objekten machen.
Die Würde des Menschen gebietet, dass Entscheidungen mit rechtlicher Wirkung oder ähnlicher Beeinträchtigung nicht allein Maschinen überlassen werden. Betroffene müssen einen Anspruch auf das Eingreifen einer Person haben (Intervenierbarkeit).
(2) KI muss Diskriminierungen vermeiden.
Lernende Systeme sind im hohen Maße abhängig von den eingegebenen Daten. Durch unterschiedliche Faktoren können Algorithmen in KI‑Systemen die zugrunde liegenden Daten so bewerten, dass Diskriminierungen erlernt und sogar verstärkt werden können. Es muss eine Risikoüberwachung installiert werden, die sowohl offensichtliche als auch verdeckte Diskriminierungen erkennen kann.
(3) KI muss transparent, nachvollziehbar und erklärbar sein.
Werden personenbezogene Daten durch KI-Systeme verarbeitet, dann gilt die Rechenschaftspflicht des Verantwortlichen. Die Nachvollziehbarkeit und Erklärbarkeit des KI-Systems muss nicht nur im Hinblick auf das Ergebnis gewährleistet sein, sondern auch auf die Trainingsdaten, die Prozesse und das Zustandekommen von Entscheidungen.
(4) KI darf nur für verfassungsrechtlich legitimierte Zwecke eingesetzt werden und das Zweckbindungsgebot nicht aufheben.
Bei dieser Anforderung ist besonders zu beachten, dass sie sowohl die personenbezogenen Daten berücksichtigt, die mit dem entsprechenden KI-System verarbeitet werden, als auch die (personenbezogenen) Trainingsdaten, mit denen das entsprechende KI-System trainiert wurde.
(5) Für KI gilt der Grundsatz der Datenminimierung.
Insbesondere für das Training von KI-Systemen werden große Bestände an Trainingsdaten benötigt. Für personenbezogene Trainingsdaten gilt, dass sie stets auf das notwendige Maß beschränkt sein müssen.
(6) KI braucht Verantwortlichkeit.
Der Verantwortliche muss dafür sorgen, dass die rechtmäßige Verarbeitung, die Sicherheit der Verarbeitung, die Beherrschbarkeit des KI‑Systems und die Wahrung der Betroffenenrechte gewährleistet werden.
(7) KI benötigt technische und organisatorische Standards.
Für KI-Systeme gibt es gegenwärtig noch keine speziellen Standards. Hier ist die Entwicklung von Best Practices durch Wirtschaft und Wissenschaft mit der Begleitung der Datenschutzaufsichtsbehörden wünschenswert. Die weitere Entwicklung muss allerdings auch politisch gesteuert werden, um den Schutz der Grundrechte zu gewährleisten.
Die „Hambacher Erklärung zur Künstlichen Intelligenz“ ist als Leitdokument zum Einsatz von KI‑Systemen zu verstehen, das die grundsätzlichen Anforderungen an ein KI-System definiert, ohne Details oder konkrete Maßnahmen zur Umsetzung zu nennen. Um Verantwortlichen und Entwicklern detailliertere technische und organisatorische Maßnahmen zum Einsatz von KI-Systemen an die Hand zu geben, hat die DSK das „Positionspapier der DSK zu empfohlenen technischen und organisatorischen Maßnahmen bei der Entwicklung und dem Betrieb von KI‑Systemen“ entwickelt, das am 6. November 2019 durch die DSK beschlossen wurde.
In dem Positionspapier werden verschiedene Lebensphasen eines KI-Systems (Design & Veredelung der Daten, Training & Validierung sowie Einsatz & Rückkopplung) unterschieden. Die sieben Datenschutzanforderungen aus der Hambacher Erklärung werden aufgegriffen und unter Berücksichtigung des Lebenszyklus und mithilfe der Gewährleistungsziele des Standard-Datenschutzmodells (Tz. 6.2.3) konkretisiert. Das Ergebnis ist eine Matrix, in der pro Lebensphase und Gewährleistungsziel konkrete Anforderungen und Risiken definiert sind.

Durch diese Matrixsystematik ist eine ganzheitliche Sicht auf ein KI-System gelungen, die aufgrund der rasanten Entwicklungen nicht den Anspruch auf Vollständigkeit erheben kann, aber einen Weg aufzeigt, die komplexen Strukturen eines KI-Systems zu berücksichtigen.
Betrachtet man die unterschiedlichen „Felder“ der Matrix, z. B. das Gewährleistungsziel „Transparenz“, in den verschiedenen Phasen des Lebenszyklus eines KI-Systems, dann zeigen sich in jeder Phase die unterschiedlichen Fragestellungen zur Transparenz.
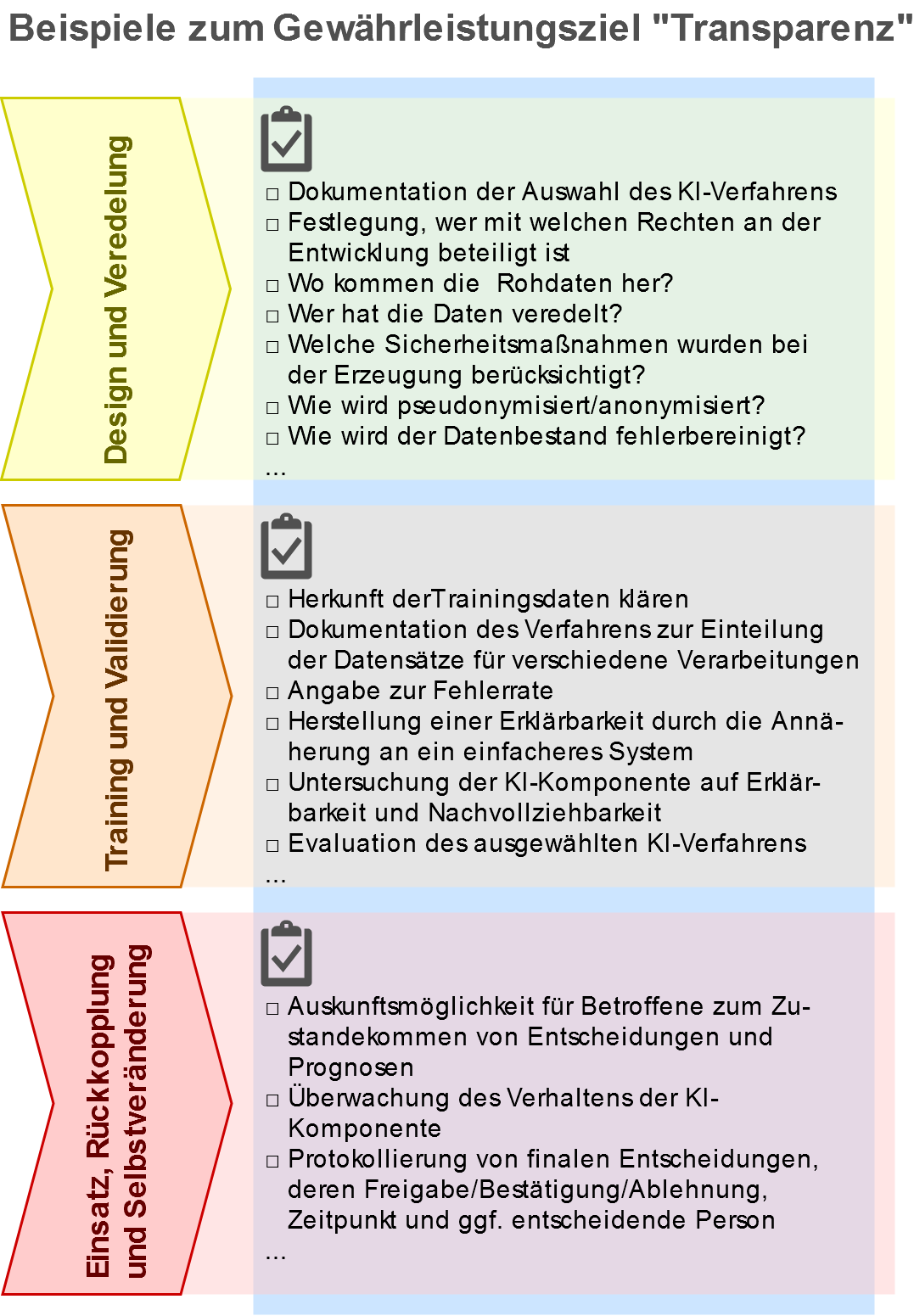
Neben der ausführlichen Beschreibung der technischen und organisatorischen Maßnahmen in Textform ist dem Positionspapier eine übersichtliche Tabelle als Anhang beigefügt, die die Maßnahmen in Kurzform den einzelnen Phasen und Gewährleistungszielen zuordnet.
Die „Hambacher Erklärung zur Künstlichen Intelligenz“ und das „Positionspapier der DSK zu empfohlenen technischen und organisatorischen Maßnahmen bei der Entwicklung und dem Betrieb von KI-Systemen“ sind unter den folgenden Links abrufbar:
Hambacher Erklärung:
https://www.datenschutzkonferenz-online.de/media/en/20190405_hambacher_erklaerung.pdf [Extern]
Kurzlink: https://uldsh.de/tb38-102a
Positionspapier:
https://www.datenschutzkonferenz-online.de/media/en/20191106_positionspapier_kuenstliche_intelligenz.pdf [Extern]
Kurzlink: https://uldsh.de/tb38-102b
Was
ist zu tun?
Anwender und Entwickler von
KI-Systemen sollten die Hinweise aus der „Hambacher Erklärung zur Künstlichen
Intelligenz“ und aus dem Positionspapier berücksichtigen. Zudem sollte im
KI-Bereich ein Schwerpunkt der Forschung auf Realisierungen und Verbesserungen
von KI-Systemen im Sinne der Grundrechte und Werte gelegt werden – hierfür
könnten Fördergeber Anreize bieten.
10.3 Nutzung von DNS-over-HTTPS
Neuere Browserversionen enthalten Funktionen, die eine Namensauflösung durch das Domain Name System (DNS) mittels kryptografisch gesicherter Verbindungen (TLS) ermöglichen. Während dieser Ansatz einerseits eine bekannte Schwachstelle der Internetnutzung anpackt, können andererseits neue Probleme entstehen.
In der Vergangenheit kam beim DNS wenig kryptografische Sicherheit zum Einsatz, was Angreifende aller Couleur immer wieder ausnutzen, um beispielsweise zu überwachen, mit welchen Diensten Nutzerinnen und Nutzer kommunizieren, oder um ihnen für Betrugs- oder Zensurversuche manipulierte Daten unterzuschieben. In einigen Ländern werden auf diese Weise Netzsperren versucht. Manche Provider nutzen diese Angriffsmöglichkeit gar, um ihren Kundinnen und Kunden Werbung aufzudrängen. Umgekehrt können Nutzende eigene (lokale) DNS-Server betreiben, um damit potenziell schädliche Dienste, die etwa Viren verbreiten oder User-Tracking betreiben, für das komplette Heimnetz zu unterdrücken: Dazu werden lokale DNS-Anfragen von Clients vom eigenen DNS-Server mit Sperrlisten abgeglichen. Befindet sich ein angefragter Server auf dieser Liste, so erhält der Client eine „Nullantwort“ und der Verbindungsaufbau unterbleibt. Technisch sind diese Mechanismen ähnlich wie die oben genannten Netzsperren oder Umleitungen durch Provider – mit dem Unterschied, dass hier die Nutzenden selbst entscheiden.
Domain Name System
(DNS)
DNS ist der zentrale Dienst im
Internet, der es ermöglicht, Namen wie z. B. www.datenschutzzentrum.de in
IP-Adressen aufzulösen, sodass Datenpakete an das richtige Ziel versendet
werden können. DNS ist vorrangig auf Robustheit ausgelegt. Unzählige Server
bieten den Dienst an und gleichen sich asynchron miteinander ab. Dadurch
verbreiten sich geänderte Einträge zwar mit einer gewissen Trägheit, dafür
erhält man aber eine hohe Verfügbarkeit. Fällt ein DNS-Server aus, kann auf
andere DNS-Server ausgewichen werden.
Mit DNS-over-TLS (DoT) und DNS-over-HTTPS (DoH) wurden zwei Standards vorgeschlagen, um DNS-Anfragen durch verschlüsselte Übertragung gegen Ausspähung und Manipulation zu schützen. Bei DoT wird das bisherige DNS-Protokoll – vereinfacht ausgedrückt – lediglich um die Verwendung von TLS für die Verbindung erweitert (kryptografische Absicherung der Netzpakete). Bei DoH wird eine HTTPS-Verbindung aufgebaut, wie sie auch zum Abruf von Webseiten genutzt wird. Dies hat den zusätzlichen Vorteil, dass für Angreifer mit lesendem Zugriff die Namensauflösung nicht von anderen Datentransfers im Web unterscheidbar ist. Durch den zusätzlich zum DNS zu betreibenden Webserver, um DoH als Dienst anzubieten, eröffnen sich aufgrund der zusätzlichen Komplexität dabei allerdings neue Angriffsmöglichkeiten, sodass ein erhöhter Aufwand für eine fortwährende Absicherung im Betrieb zu erwarten ist.
Während die Namensauflösung per DNS üblicherweise durch das Betriebssystem erfolgt, wird DoH derzeit in Browsern implementiert. Dies bietet den Vorteil, dass auch in Umgebungen mit zensierenden DNS-Servern, die einem (Betriebs-)System zwangsweise zugewiesen werden, ein unmanipulierter DNS-Server durch den Browser leichter anzusprechen ist. Damit sollen Zensurmaßnahmen, wie man sie in autoritären Staaten findet, leichter umgehbar sein.
Werden Browser allerdings so ausgeliefert, dass sie als Voreinstellung DoH nutzen, erschwert dies eine Integration in lokalen Netzen, da lokale Servernamen dann nicht in IP-Adressen aufgelöst werden können. Auch die beschriebenen Schutzmaßnahmen vor Schadsoftware und User-Tracking durch lokale DNS-Server greifen dann nicht mehr. Insbesondere dann, wenn alle Browser auf einen einzigen DoH-Server verwiesen werden, ergeben sich sogar deutliche Vertraulichkeitsprobleme. Denn es fallen sehr viele Informationen darüber, welche Systeme mit welchen Diensten kommunizieren, an wenigen zentralen Stellen an. Nicht alle Nutzenden sind in der Lage, diese Problematik zu überblicken, geschweige denn selbst technisch Abhilfe zu schaffen. Die bisherige DNS-Landschaft mit vielen verteilten Systemen bietet daher klare Vorteile. Wichtig ist hier, dass auch künftig die Wahl des DNS-Servers in der Hand der Nutzenden bzw. der Geräteadministration bleibt. Keinesfalls sollte eine DNS-Vorauswahl fest im Betriebssystem verankert werden. Dies ist gerade im Hinblick auf das Unternehmen Google relevant, das als Anbieter sowohl eines Betriebssystems als auch eines DNS-Dienstes eine solche Kopplung in Erwägung ziehen könnte.
Sofern Browser und Betriebssystem (bzw. andere Anwendungen auf dem System) jeweils unterschiedliche DNS-Server nutzen, kann dies nicht nur zu deutlicher Verwirrung bei den Nutzenden führen; auch die Funktionen von Sicherheitssoftware bzw. anderen Schutzmaßnahmen könnten dadurch beeinträchtigt werden.
Andere Erweiterungen des DNS sind schon etwas länger verfügbar, haben sich aber auch noch nicht flächendeckend durchgesetzt. Mit den „Domain Name System Security Extensions“ (DNSSEC) sowie ergänzend „DNS-based Authentication of Named Entities“ (DANE) stehen Hilfsmittel bereit, um die Einträge im DNS mit digitalen Signaturen zu versehen, sodass Manipulationen bemerkbar werden. Auf diese Weise können auch TLS-Zertifikate an Domain-Namen gebunden und gegen unbefugte Austausche gesichert werden (37. TB, Tz. 10.1). Leider werden diese Verfahren noch nicht von allen Domain-Anbietenden unterstützt. Zudem sind noch nicht alle DNS-nutzenden Instanzen in der Lage, Einträge darüber zu validieren. Auch die Signalisierung an die Nutzenden, wenn eine Manipulation erkannt wird, ist noch eine Baustelle.
Was
ist zu tun?
Die DNS-Nutzung und damit auch deren
verschlüsselnde Abwicklung sollten nicht auf Browser-, sondern auf Systemebene
erfolgen. Die Hersteller von Betriebssystemen sind daher aufgefordert, DoT und
DoH zu implementieren (sofern nicht schon geschehen). Browser sollten nicht auf
wenige zentrale DoH-Server voreingestellt sein. Die Betreiber von DNS-Resolvern
sollten zeitnah auf verschlüsselnde Dienste umstellen. Domain-Anbietende
sollten DNSSEC und DANE unterstützen.
10.4 Verschlüsselte Kommunikation mit Behörden
Immer noch ist die verschlüsselte Kommunikation mit Behörden ein schwieriges Pflaster, da es weiterhin an der Etablierung von Verschlüsselungsstandards fehlt bzw. etablierte Standards aus verschiedenen Gründen nicht genutzt werden.
Ein weiteres Problem ist häufig die Eilbedürftigkeit. Zwar kann man zu Recht von Behörden und anderen öffentlichen Stellen verlangen, eine regelmäßige Kommunikation untereinander adäquat durch Verschlüsselungsverfahren abzusichern, etwa durch den Austausch von Zertifikaten oder PGP-Schlüsseln oder über die Bereitstellung von Webportalen über HTTPS-Verbindungen und Zugriffskontrollen. Dies gilt auch für die Kommunikation von Behörden mit Personen oder Organisationen, die im Auftrag oder für Behörden tätig sind und dabei eigene Technik verwenden, etwa Betreuungspersonen für Jugendliche oder Lehrkräfte. Zwar wären übergreifende sichere Kommunikationsverfahren gut, doch in der Praxis sind heutzutage meist individuelle Absprachen und Lösungen nötig.
Doch wie kann man vorgehen, wenn spontan eine dringende Kommunikation mit einem Partner notwendig ist, mit dem noch kein Verfahren etabliert wurde, etwa die Verwaltung dringend Hilfe leisten muss oder will und es einer eiligen Klärung etwa bei einem Rentenversicherungsträger bedarf? Ebenso wie man bedenkenlos zum Telefon greift oder sich bei der Briefpost auf die Sicherheit der Infrastruktur verlässt, liegt die Nutzung von Messengern, E-Mail oder cloudbasierten Datei-Sharingdiensten nahe. In diesen Fällen sind häufig Dienstleister außerhalb des Geltungsbereichs der DSGVO und des Telekommunikationsgesetzes beteiligt, die zumindest teilweise auch Inhaltsdaten analysieren. Daher sind diese Verfahren trotz ihrer technischen Einfachheit ohne datenschutzrechtliche Analyse nicht geeignet, spontan ausgewählt zu werden.
Ein Ausweg besteht darin, zumindest vorab einige dieser Verfahren zu sichten und zu prüfen – dann kann man im Bedarfsfall auf ein Portfolio zurückgreifen und findet vielleicht ein Verfahren, dass für beide Kommunikationspartner nutzbar ist. Kommen dabei webbasierte Dienste zum Einsatz, dürften diese für die Kommunikationspartner zumindest aus technischer Sicht leicht nutzbar sein, ohne dass die Installation von Apps oder Programmen notwendig ist. Oder es finden sich Verfahren, die vielleicht nicht von jedem Arbeitsplatz aus nutzbar sind, aber dennoch eine höhere Sicherheit aufweisen als eine unverschlüsselte E-Mail: So sind beispielsweise viele öffentliche Stellen über De-Mail oder das elektronische Behördenpostfach erreichbar.
Perspektivisch sind Multikanallösungen geeignet, die den Beschäftigten in den Behörden Empfang und Versand von Nachrichten am Arbeitsplatz erlauben – losgelöst von den Details des elektronischen Transports und der Verschlüsselung.
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


